

TV and film editors could use powerful editing technologies to forgo costly reshoots. | Adobe Stock/Framestock
Imagine typing words into a text editor and watching on a nearby television as a well-known celebrity speaks those words within seconds.
Computer graphics expert Maneesh Agrawala has imagined it and has created a video editing software that can do it, too. Given enough raw video, Agrawala’s application can produce polished, photorealistic video of any person saying virtually anything he types in.
While he acknowledges concerns about manufactured “deep fakes” of political leaders or others speaking words they never said, Agrawala chooses to focus on the profound upside. He envisions the television and film industries using his technology to forgo costly reshoots, for instance, or medical professionals helping people with damaged vocal cords regain their natural voices.
In the end, while ethical and legal frameworks are being developed to address deep fakes with all due seriousness they deserve, Agrawala says the benefits of the technology, and his passion for it, gets at the most basic of all human endeavors — better communication. Agrawala tells host Russ Altman, associate director of the Stanford Institute for Human-Centered Artificial Intelligence, all about it in this episode of Stanford Engineering’s The Future of Everything podcast. Listen and subscribe here.
Stanford HAI's mission is to advance AI research, education, policy and practice to improve the human condition. Learn more.
More News Topics
Related Content
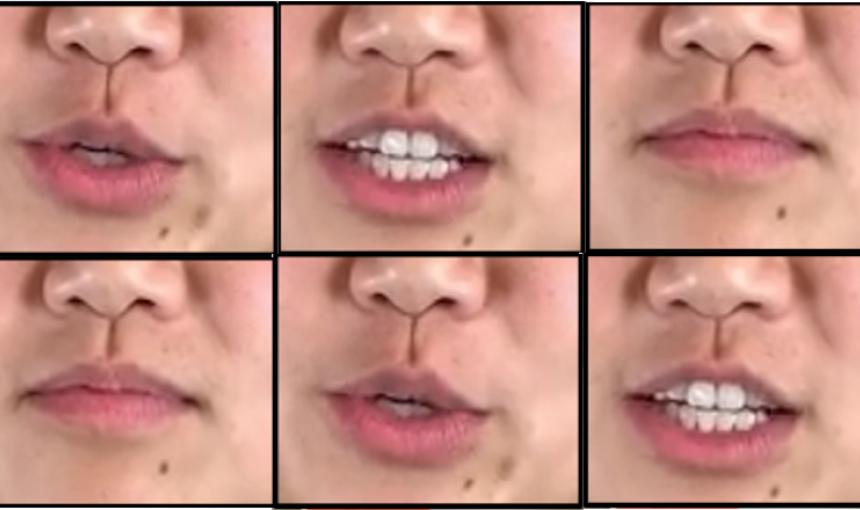
Using AI to Detect Seemingly Perfect Deep-Fake Videos
But a Stanford professor says the cat-and-mouse game is far from over.

How to Build a Likable Chatbot
Consumers have consistent personality preferences for their online friends, new research shows.

Scrutinizing Cable News: A Stanford AI Tool Increases Transparency into Broadcasters' Editorial Decisions
The Stanford Cable TV News Analyzer uses AI to search transcripts and calculate the screen time of public figures...