

DALL-E
Language plays a central role in how we communicate, how we learn and teach, how we organize and take political action, and how we convey the emotions and complexities of our lives. Language models, which derive their power from colossal amounts of language data, epitomize the broader paradigm shift toward foundation models, machine learning models that can be adapted to an impressively wide range of tasks. Organizations such as Google, Microsoft, and OpenAI expend extraordinary capital to build these models (sometimes millions of dollars for a single model), which then power products that impact billions of people. These models are at the center of the emerging ecosystem of established products like Google Search, new experiences like GitHub CoPilot, and the next generation of startups like Adept, Character, and Inflection. These models have already been used to co-author Economist articles and award-winning essays, co-create screenplays, and co-construct testimonies before the U.S. Senate. Meanwhile, there has been extensive discussion about their risks: They can be toxic, dishonest, possibly used to spread disinformation, and the practices surrounding their data and their deployment raise serious legal and ethical issues.
With all the excitement and fear surrounding language models, we must be measured. We need to know what this technology can and can’t do, what risks it poses, so that we can both have a deeper scientific understanding and a more comprehensive account of its societal impact. Transparency is the vital first step towards these two goals.
But the AI community lacks the needed transparency: Many language models exist, but they are not compared on a unified standard, and even when language models are evaluated, the full range of societal considerations (e.g., fairness, robustness, uncertainty estimation, commonsense knowledge, disinformation) have not be addressed in a unified way.
At the Center for Research on Foundation Models, we have developed a new benchmarking approach, Holistic Evaluation of Language Models (HELM), which aims to provide the much needed transparency. We intend for HELM to serve as a map for the world of language models, continually updated over time, through collaboration with the broader AI community.
Holistic Evaluation
We emphasize being holistic in evaluating language models. But what does it mean to benchmark language models holistically? Unlike previous AI systems, language models are general-purpose text interfaces that could be applied across a vast expanse of scenarios from question answering to summarization to toxicity detection. And for each use case, we have a broad set of desiderata: models should be accurate, robust, fair, efficient, and so on.
We believe holistic evaluation involves three elements:
- Broad coverage and recognition of incompleteness. Given language models' vast surface of capabilities and risks, we need to evaluate language models over a broad range of scenarios. However, it is not possible to consider all the scenarios, so holistic evaluation should make explicit all the major scenarios and metrics that are missing.
- Multi-metric measurement. Societally beneficial systems are characterized by many desiderata, but benchmarking in AI often centers on one (usually accuracy). Holistic evaluation should represent these plural desiderata.
- Standardization. Our object of evaluation is the language model, not a scenario-specific system. Therefore, in order to meaningfully compare different LMs, the strategy for adapting an LM to a scenario should be controlled for. Furthermore, we should evaluate all the major LMs on the same scenarios to the extent possible.
Overall, holistic evaluation builds transparency by assessing language models in their totality. We strive for a fuller characterization of language models to improve scientific understanding and orient societal impact.
1. Broad Coverage and the Recognition of Incompleteness
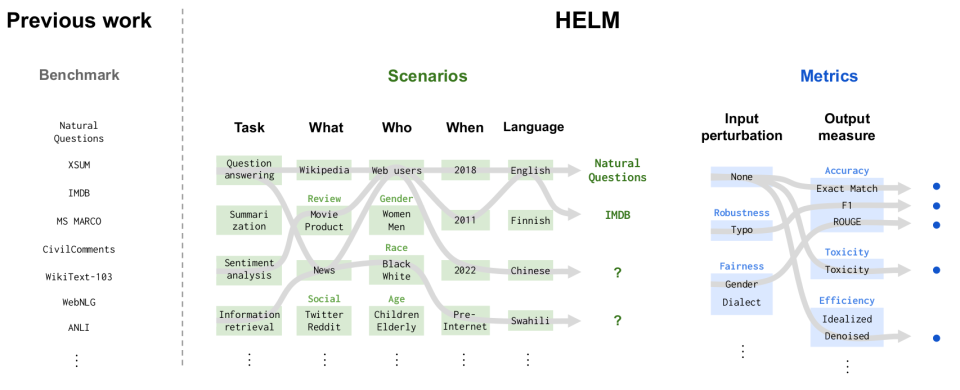
To grapple with the vast capability surface of language models, we first taxonomize the space of scenarios (where LMs can be applied) and metrics (what we want them to do). A scenario consists of a task, a domain (consisting of what genre the text is, who wrote it, and when it was written), and the language. We then prioritize a subset of scenarios and metrics based on societal relevance (e.g., user-facing applications), coverage (e.g., different English dialects/varieties), and feasibility (i.e., we have limited compute). In contrast to prior benchmarks (e.g., SuperGLUE, EleutherAI LM Harness, BIG-Bench), which enumerate a set of scenarios and metrics, situating our selection of scenarios in a larger taxonomy makes explicit what is currently missing. Examples for what we miss in the first version of HELM include: languages beyond English, applications beyond traditional NLP tasks such as copywriting, and metrics that capture human-LM interaction.
2. Multi-metric Measurement
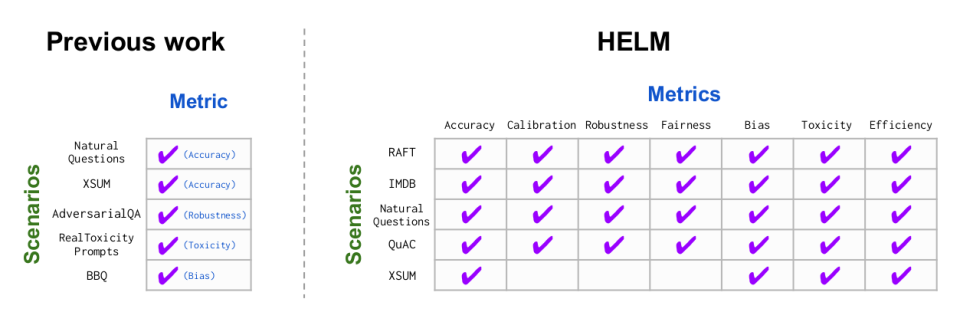
Most existing benchmarks consider scenarios with a single main metric (usually accuracy), relegating the evaluation of other desiderata (e.g., toxicity) to separate scenarios (e.g., RealToxicityPrompts). We believe it is integral that all of these desiderata be evaluated in the same contexts where we expect to deploy models. For each of our 16 core scenarios, we measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency). The multi-metric approach makes explicit potential trade-offs and helps ensure the non-accuracy desiderata are not treated as second-class citizens to accuracy.
In addition, we perform targeted evaluations: 26 finer-grained scenarios that isolate specific skills (e.g., reasoning, commonsense knowledge) and risks (e.g., disinformation, memorization/copyright). This includes 21 scenarios that are either entirely new in this work (e.g., WikiFact) or that have not been used in mainstream language model evaluation (e.g., the International Corpus of English).
3. Standardization
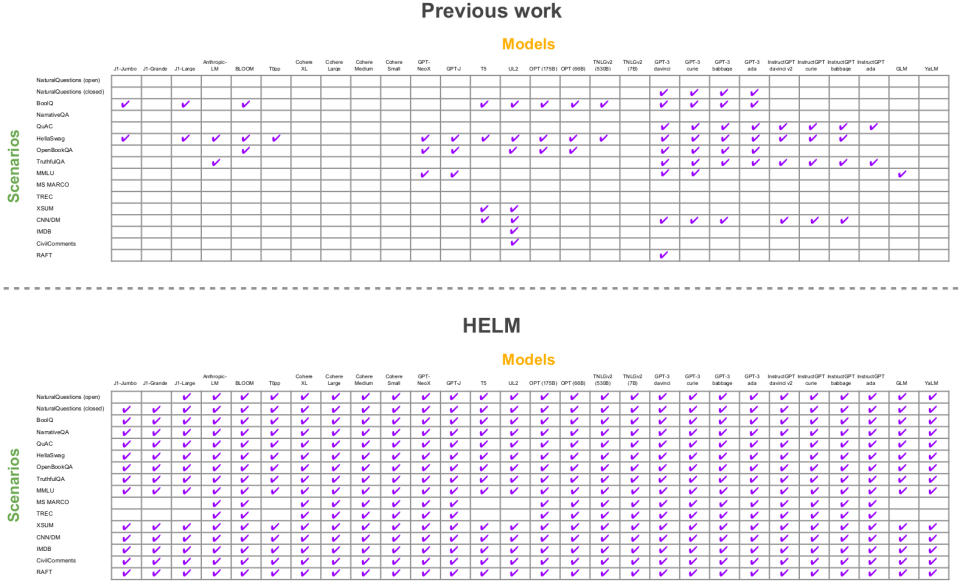
As language models become the substrate for language technologies, the absence of an evaluation standard compromises the community’s ability to see the full landscape of language models.
As an example, of the 405 datasets evaluated across all major language modeling works at the time of writing, the extent to which models evaluate on these datasets is uneven. Different models are often evaluated on different scenarios: Models such as Google’s T5 (11B) and Anthropic’s Anthropic-LM (52B) were not evaluated on a single dataset in common in their original works. Several models (e.g., AI21 Labs’ J1 Grande (17B), Cohere’s Cohere-XL (52B), Yandex’s YaLM (100B)) essentially do not report public results (to our knowledge).
To rectify this status quo, we evaluated 30 models from 12 providers: AI21 Labs, Anthropic, BigScience, Cohere, EleutherAI, Google, Meta, Microsoft, NVIDIA, OpenAI, Tsinghua University, and Yandex. These models differ in public access: Some are open (e.g., BigScience’s BLOOM (176B)), others are limited access via API (e.g., OpenAI’s GPT-3 (175B)), and still others are closed (e.g., Microsoft/NVIDIA’s TNLGv2 (530B)). For our 16 core scenarios, models were previously evaluated on 17.9% of our scenarios (even after compiling evaluations dispersed across different prior works), which we improve to 96.0%.
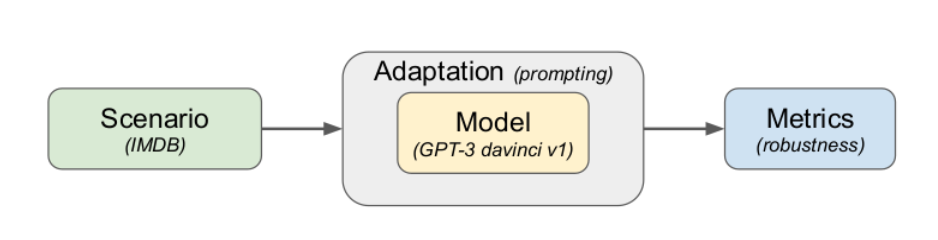
To benchmark these models, we must specify an adaptation procedure that leverages a general-purpose language model to tackle a given scenario. In this work, we adapt all language models through few-shot prompting, as pioneered by GPT-3. We chose simple and generic prompts to encourage the development of generic language interfaces that don’t require model-specific incantations. We encourage future work to explore other adaptation methods such as more sophisticated forms of prompting, prompt-tuning, and more interactive approaches.
Our Findings
We ran more than 4900 evaluations of different models on different scenarios. This amounts to over 12 billion tokens of model inputs and outputs, spanning 17 million model calls, which costs $38K for the commercial models (under current pricing schemes) and almost 20K GPU hours for the open models, which were run on the Together Research Computer. Through this, we identify 25 top-level findings, from which we extract five salient points:
- Instruction tuning, the practice of fine-tuning LMs with human feedback, pioneered by OpenAI and Anthropic, is highly effective in terms of accuracy, robustness, and fairness, allowing smaller models (e.g., Anthropic-LM (50B)) to compete with models 10x the size (Microsoft/NVIDIA’s TNLG v2 (530B)). Note that within a model family, scaling up still helps. Unfortunately, how the instruction tuning was performed for these models is not public knowledge.
- Currently, open models (e.g., Meta’s OPT (175B), BigScience’s BLOOM (176B), Tsinghua University’s GLM (130B)) underperform the non-open models (e.g., OpenAI’s InstructGPT davinci v2, Microsoft/NVIDIA’s TNLG v2 (530B), and Anthropic-LM (52B)). Open models have improved dramatically over the last year, but it will remain to be seen how these dynamics unfold, and what this says about power in the language modeling space.
- We find that (average) accuracy is correlated with robustness (e.g., inserting typos) and fairness (e.g., changing dialects), though there are some scenarios and models where there are large drops in robustness and fairness. Our multi-metric approach allows us to monitor these deviations and ensure we do not lose sight of considerations beyond accuracy. See Section 8.1 of the paper for more details.
- The adaptation strategy (e.g., prompting) has a large effect, and the best strategy is scenario- and model-dependent. Sometimes even the qualitative trends themselves change, such as the relationship between accuracy and calibration (which captures whether the model knows what it doesn’t know). This shows the importance of standardized, controlled evaluations, so that we can attribute performance to the model versus the adaptation strategy. This result also shows that models are not yet interoperable, an important property for building a robust ecosystem of natural language interfaces. See Section 8.2 of the paper for more details.
- We found human evaluation essential in some cases. On summarization, we find that language models produce effective summaries (as measured via human evaluation), but the reference summaries in standard summarization datasets (e.g., CNN/DM, XSUM) are actually worse (under the same human evaluations). Models fine-tuned on these datasets appear to do well according to automatic metrics such as ROUGE-L, but they also underperform few-shot prompting of language models. This suggests that better summarization datasets are desperately needed. For disinformation generation, We find that InstructGPT davinci v2 and Anthropic-LM v4-s3 (52B) are effective at generating realistic headlines that support a given thesis, but results are more mixed when prompting models to generate text encouraging people to perform certain actions. While using language models for disinformation is not yet a slam dunk, this could change as models become more powerful. Thus, periodic benchmarking is crucial for tracking risks. See Section 8.5 of the paper for more details.
Conclusion
These findings represent the current snapshot of the language modeling landscape. The field of AI moves swiftly with new models being released continuously (for example, Meta just released Galactica, a new 120B parameter model yesterday, and we have yet to evaluate AI21 Labs and Cohere’s newest models, which became available within the past week). So what might be true today might not be true tomorrow.
And there are still models such as Google’s PaLM and DeepMind’s Chinchilla that we do not have access to. We also do not know how existing models such as OpenAI’s InstructGPT davinci v2 was trained despite being able to probe their behavior via APIs. So as a community, we are still lacking the desired level of transparency, and we need to develop the community norms that provide researchers with adequate access in a responsible manner.
While we strived to make HELM as holistic and complete as possible, there will always be new scenarios, metrics, and models. For this reason, HELM by design foregrounds its incompleteness, and we welcome the community to highlight any further gaps, help us prioritize, and contribute new scenarios, metrics, and models. The history and trajectory of AI benchmarking aligns with institutional privilege and confers decision-making power. Benchmarks set the agenda and orient progress: We should aspire for holistic, pluralistic, and democratic benchmarks. We hope the community will adopt, develop, and interrogate HELM going forward to meet that aspiration. Let us work together to provide the much needed transparency for language models, and foundation models more generally.
Transparency begets trust and standards. By taking a step towards transparency, we aim to transform foundation models from an immature emerging technology to a reliable infrastructure that embodies human values.
Where to go from here:
- Website: Explore the latest HELM results and drill down from the aggregate statistics to see the raw underlying prompts and model predictions.
- Paper: Read more about the principles of HELM and analysis of results.
- GitHub repository: Download the code and use HELM for your research. It is easy to add new scenarios/metrics and inherit the infrastructure for performing rigorous, systematic experiments.
Acknowledgements
HELM was the year-long effort of a team of 50 people. Many others also contributed valuable feedback and guidance; see the paper for the full list of contributors and acknowledgements. We would like to especially thank AI21 Labs, Cohere, and OpenAI for providing credits to run experiments on their limited-access models, as well as Anthropic and Microsoft for providing API access to their closed models. We are grateful to BigScience, EleutherAI, Google, Meta, Tsinghua University, and Yandex for releasing their open models, and to Together for providing the infrastructure to run all the open models. Finally, we would also like to thank Google providing financial support through a Stanford HAI-Google collaboration.