

If ChatGPT prescribed you a drug, would you take it? The answer is probably no, at least for now. The question then becomes, what might convince you otherwise.
At a much larger scale, this is a question that many hospital technology professionals are struggling with today. Are large language models (LLMs), which are a kind of foundation model (FM), worth the investment given the difficulty of ensuring their factual correctness and robustness?
While adopting foundation models into healthcare has immense potential, until we know how to evaluate whether these models are useful, fair, and reliable, it is difficult to justify their use in clinical practice. To complicate the matter further, foundation models in healthcare lack the shared evaluation frameworks and datasets that have underpinned progress in other machine learning fields such as natural language processing (NLP) and computer vision.
We reviewed more than 80 different clinical foundation models — built from a variety of healthcare data such as electronic health records (EHRs), textual notes written by providers, insurance claims, etc. — and found notable limitations in how these models are being evaluated and a large disconnect between their evaluation regimes and true indications of clinical value.
Read the full study, The shaky foundations of large language models and foundation models for electronic health records
If we believe that foundation models can help both doctors and patients, then we need to conduct evaluations that rigorously test these beliefs. Taking inspiration from Stanford CRFM’s HELM project, which was the first benchmark to evaluate LLMs trained on non-clinical text for a range of metrics beyond accuracy, we believe that a similar “medical-HELM” is needed to tie evaluation of LLMs and FMs writ large with use cases that matter in delivering better care to patients.
Here we outline the state of foundation models in healthcare, examine how these models are currently being evaluated, and finally define a framework for improving their evaluation.
1. What Are Foundation Models for Healthcare?
While there is clearly no shortage of excitement around foundation models in healthcare, the exact definition of what people mean by “clinical foundation model” is a bit fuzzy. It is helpful to think of foundation models in healthcare in two broad categories.
The first are models that are trained on clinical/biomedical text and output text in response to a user’s input. We refer to such foundation models as Clinical Language Models, or CLaMs, which ingest clinical text and output clinical text. For example, a CLaM could extract drug names from a doctor’s note, automatically reply to patient questions, summarize medical dialogues, or predict mechanical ventilation needs from learned textual representations
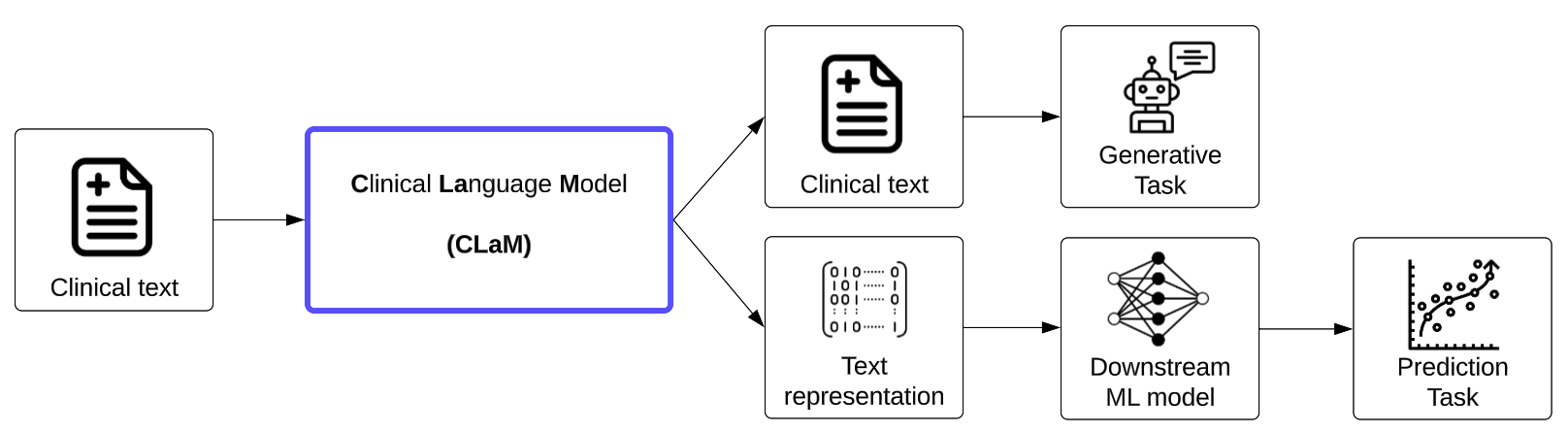
Figure 1. The inputs and outputs of Clinical Language Models (CLaMs).
While general-purpose language models (e.g., ChatGPT, Bloom, GPT-3, etc.) can be useful for clinical tasks, they tend to underperform medical-specific CLaMs, and thus we exclude them from this discussion.
The second class of foundation models in healthcare are Foundation models for Electronic Medical Records (FEMRs), which are trained on the entire timeline of events in a patient's electronic medical record and generate not text but machine-understandable representations for patients.

Figure 2. The inputs and outputs of Foundation models for Electronic Medical Records (FEMRs).
Their inputs can potentially include billing codes, lab values, insurance claims, clinical text, images, and waveforms, but in practice FEMRs are typically limited to the single modality of structured billing codes. The output of these models is a dense vector representation of an individual patient (also referred to as a “patient embedding”) which can be used for building downstream models that are more accurate and also more robust to dataset drift for tasks like 30-day readmissions risk or inpatient mortality.
In an earlier blog post, we summarized the key benefits of both CLaMs and FEMRs, which we reproduce briefly below. Compared with traditional machine learning methods, foundation models have the potential to…
- Have better predictive accuracy
- Need less labeled data
- Enable simpler and cheaper model deployment
- Exhibit emergent capabilities that unlock entirely new clinical application areas (e.g. writing a coherent insurance appeal)
- More seamlessly handle multimodal data
- Offer novel interfaces for human-AI interaction (e.g. prompting)
2. What Is the Current State of Foundation Models in Healthcare?
We surveyed the literature and identified more than 80 distinct healthcare foundation models that have been published.
For CLaMs, we found that models trained on true clinical text (green rows in Figure 3 below) — i.e., documents written during the course of care delivery — are almost entirely trained on MIMIC-III, which is a dataset of approximately 2 million notes written between 2001 and 2012 in the ICU of the Beth Israel Deaconess Medical Center. This overrepresentation is because MIMIC-III is one of the only public datasets of clinical notes available to researchers.
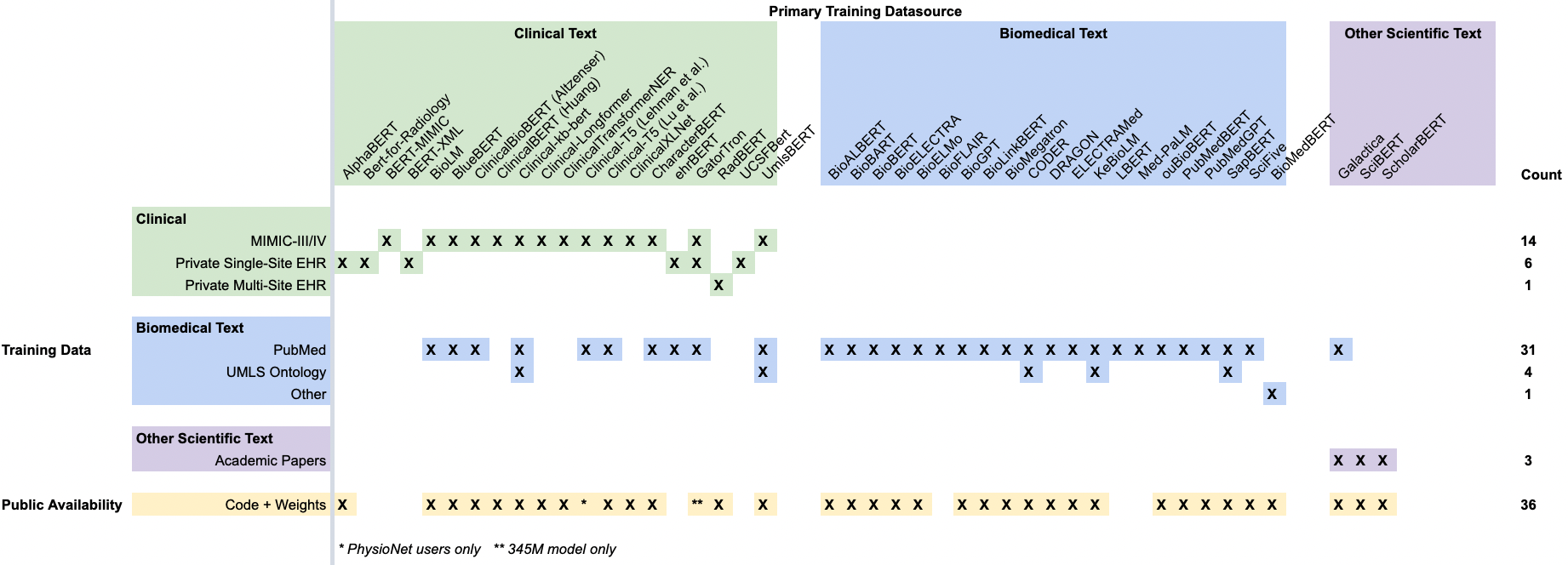
Figure 3. A summary of CLaMs and their training data. Each column is a specific CLaM, grouped by the primary type of data they were trained on. Each row is a specific dataset, with the exception of the bottom-most row, which records whether a model’s code and weights have been published.
Training on “biomedical text” (blue rows) typically means training on PubMed articles. While most models trained on clinical text (green columns) are also trained on PubMed, none of the “biomedical models” (blue columns) are trained on any clinical text.
The majority of CLaMs are publicly accessible via repositories like HuggingFace, which is a public hub for NLP research. Unfortunately, the exceptions are the very CLaMs trained on large-scale private EHR datasets that seem to have the best performance -- ehrBERT, UCSF-Bert, and GatorTron.
Meanwhile, most FEMRs are trained on either small public EHR datasets (again MIMIC-III, which only has 40,000 patients) or a single private hospital’s EHR database, with the exception of Rajkomar et al., which uses data from both University of California, San Francisco (UCSF) and University of Chicago Medicine (UCM).

Figure 4. A summary of FEMRs and their training data. Each column is a specific FEMR, grouped by the primary modality of data they were trained on. Each row is a specific dataset, with the exception of the bottom-most row, which records whether a model’s code and weights have been published.
In terms of data modalities, most FEMRs are unimodal and consider only structured codes (red columns) in a patient’s timeline, such as ICD-10, SNOMED, LOINC, etc. This reliance on structured codes reduces a model’s ability to generalize across different health systems that might use different database schemas with varying coding practices.
While CLaMs benefit from the standardized distribution channels pioneered by HuggingFace for NLP models, FEMRs lack a common mechanism for distributing models to the broader research community. This can be clearly seen in the scarsity of the bottom row in Figure 4 compared with the density of the bottom row in Figure 3. Few FEMRs have had their model weights published, meaning researchers must re-train these models entirely from scratch to use them or verify their performance.
3. How Are Healthcare Foundation Models Currently Being Evaluated?
Today, clinical foundation models are evaluated on tasks because they are simple to set-up, and these tasks do provide diagnostic insights on model behavior. However, these evaluation settings provide limited insight on the substantially grander promise of foundation models to improve healthcare as a potentially “categorically different” technology, and offer little evidence demonstrating the tangible utility from deploying these models.
In general, evaluating foundation models has proved challenging, resulting in a recent push for Holistic Evaluation of Language Models (HELM) to improve the transparency of LLMs. The field of healthcare is no exception.
The majority of CLaMs are being evaluated on traditional NLP-style tasks (e.g., named entity recognition, relation extraction, sentence similarity) using text sourced from PubMed or MIMIC-III.
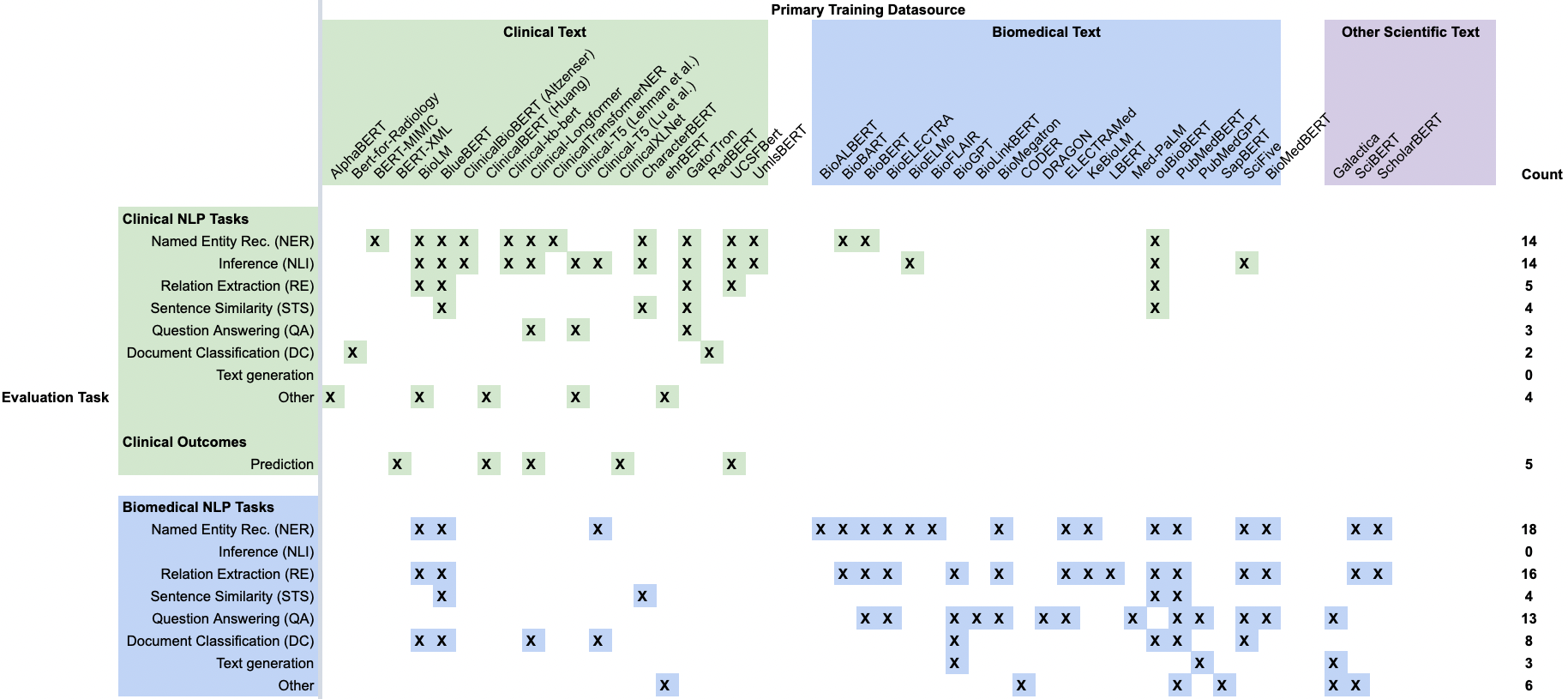
Figure 5. A summary of the tasks that each CLaM was evaluated on in its original publication. Each column is a specific CLaM, grouped by the primary type of data they were trained on. Each row is a type of evaluation task. Green rows are tasks that are sourced from clinical text, while blue rows are evaluation tasks sourced from biomedical text.
Similar to how the source of a model’s training data is an important consideration, the source of a model’s evaluation task is also important. Evaluation tasks derived from clinical text (green rows) are extremely different from tasks derived from biomedical text (blue rows), as clinical text contains numerous idiosyncrasies not found in biomedical text or other domains. Alarmingly, roughly half of all “clinical language models” (blue and purple columns) aren’t actually being validated on clinical text, and thus they may be greatly overestimating their performance in a hospital setting.
Even among the NLP tasks sourced from clinical text, there is still a significant disconnect between the abilities that these tasks measure and the actual value that would come from deploying such models.
To be clear, NLP tasks like question answering, named entity recognition, and text generation are extremely useful core diagnostics for models. However, the poor quality of their underlying data (almost entirely drawn from PubMed or MIMIC-III), their small size (typically only a few thousand examples of repetitive data), and their necessarily limited problem scope prevent them from substantiating the grander promises surrounding foundation models in medicine. As a concrete example, the leap from “Model A achieves state-of-the-art precision on named entity recognition on 2,000 discharge notes taken from MIMIC-III” to “Model A should be deployed across all 39 Kaiser Permanente hospitals to identify patients at risk of suicide” is fairly large.
To more clearly illustrate this disconnect, we recorded which CLaMs have actually been tested on their ability to deliver the six aforementioned value propositions of foundation models in Figure 6 below.

Figure 6. A recreation of Figure 5, but with the rows containing evaluation tasks from the literature replaced with the six primary foundation model benefits. While almost all CLaMs have demonstrated the ability to improve predictive accuracy over traditional approaches, there is scant evidence for the other five value propositions.
Most CLaMs are being evaluated on tasks that only measure one key value proposition — improved predictive accuracy on specific tasks — while ignoring many of the other potential benefits of foundation models, such as simplified deployment or reducing the need for labeled data. There is a clear gap in our understanding of what CLaMs can do versus what CLaMs can do that is valuable to health systems.
Evaluation of FEMRs is in an even poorer state than that of CLaMs. That is because FEMRs lack a set of “canonical” evaluation formats, which makes it nearly impossible to compare the performance of these models across publications.
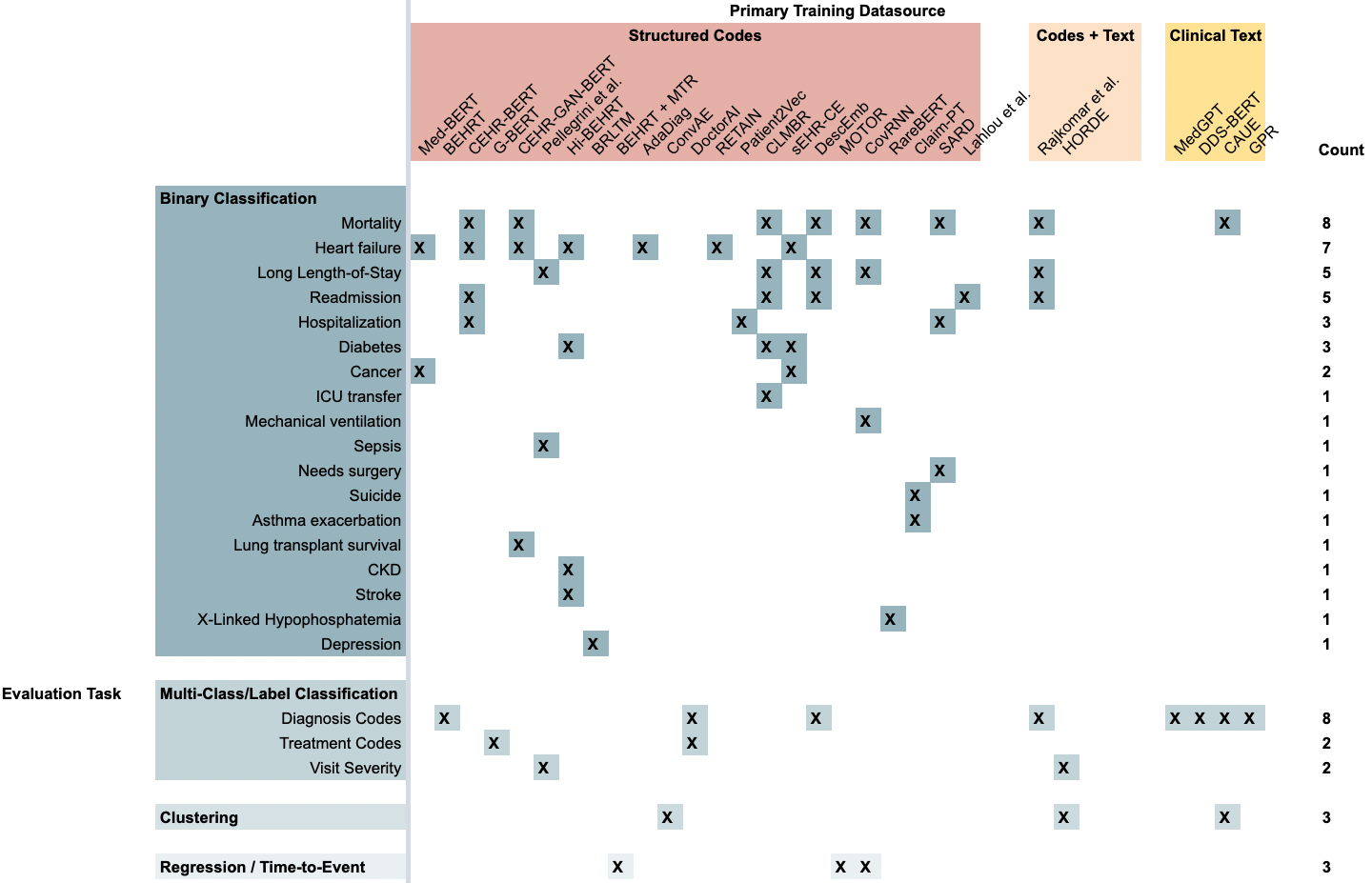
Figure 7. A summary of the tasks that each FEMR was evaluated on in its original publication. Each column is a specific FEMR, grouped by the primary modality of data they were trained on. Each row is a type of evaluation task, grouped by the format of predictions generated by the model.
FEMRs are being evaluated using a broad range of binary classification tasks, with the most popular prediction tasks being mortality, heart failure, long length-of-stay, and 30-day hospital readmission. The most popular non-binary-classification task is to predict the next diagnosis code in a patient’s timeline given their medical history. Again, FEMRs are primarily being evaluated on these tasks because it is relatively simpler to automatically evaluate models on these tasks, not because these tasks measure novel properties of foundation models that would justify their implementation.
As we did with CLaMs, we studied the purported key benefits of foundation models. In Figure 8 below, we see that almost all evaluations of FEMRs have been focused on demonstrating their superior predictive accuracy over traditional ML models. Interestingly, the ability to use less labeled data (i.e., sample efficiency) has been fairly well documented with FEMRs, but their other benefits have gone largely unstudied.
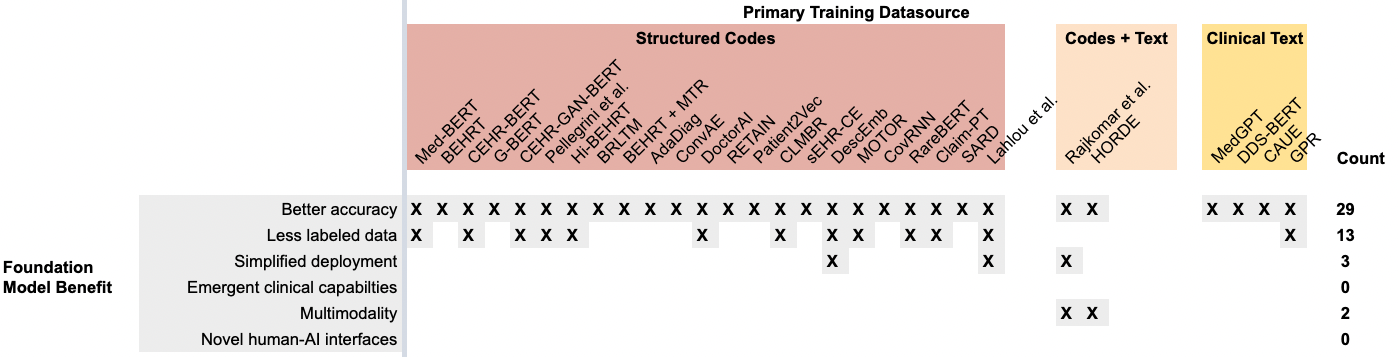
Figure 8. A recreation of Figure 7, but with the rows containing evaluation tasks from the literature replaced with the six primary foundation model benefits. While almost all FEMRs have demonstrated the ability to improve predictive accuracy over traditional approaches, there is scant evidence for the other five value propositions.
4. How Can We Create Better Evaluation Paradigms?
In light of this analysis, we believe there is a strong need for better evaluation paradigms, datasets, and shared tasks to better demonstrate the value of clinical foundation models to health systems.
We advocate for the community to develop evaluation metrics and datasets that better clarify the value propositions of FMs in healthcare by more directly grounding their outputs in clinically meaningful scenarios.
As a start, we went through the six key potential benefits of clinical foundation models and identified some evaluation metrics and tasks that could better quantify each benefit. Our proposals are listed in Figure 9. Some are fairly simple to implement (e.g., swapping metrics like precision for Top-K precision and AUROC for AUROC @ K examples), while others will require substantial effort (e.g., creating multimodal task scenarios). Please note that our proposals are by no means comprehensive, but rather meant to spark further discussion on how to better align model evaluation with demonstrations of clinical value.

Figure 9. Suggestions for how to better demonstrate the value of CLaMs and FEMRs for achieving the purported benefits of foundation models.
Concerns, but Immense Promise
FEMRs and CLaMs are being evaluated on a set of tasks that provide little information about the true potential value of these technologies to health systems over traditional machine learning/statistical models. While there is sufficient evidence that FMs enable more accurate prediction and classification, minimal work has been done to validate whether the other purported (and significantly more valuable) benefits of foundation models that have been witnessed in other domains will also be realized in healthcare. To bridge this gap, we advocate for the development of new evaluation tasks and datasets specifically geared towards elucidating the value of clinical FMs.
While we have focused on the benefits that foundation models may bring to the table, there are certainly new risks introduced by this technology. Data privacy is a significant concern with these large-scale models, as they may leak protected health information through their model weights or through prompt injection attacks. Foundation models are also much more difficult to interpret, edit, and control due to their immense size. They require high up-front costs to create, and while these costs can be amortized over many downstream applications, the return on investment (ROI) may be significantly longer than a smaller model specifically developed for a single high-value task. There are also potentially complicated regulatory requirements with deploying foundation models into the clinic, potentially falling under Software-as-a-Medical-Device guidelines. In addition to these unique risks, foundation models may also suffer from the usual risks of traditional ML models, including biases induced by mis-calibration or overfitting, as well as inducing a phenomenon known as “automation bias” in which clinicians defer to a model’s outputs even when incorrect. Developing frameworks for determining a model’s worth remains indispensable.
Despite these risks and challenges in evaluating their benefits, foundation models still hold immense promise for solving a diverse range of healthcare problems, and we are extremely excited for their continued development. We aim to further explore these ideas in future posts as part of this series on foundation models in healthcare.
Read more about the role of foundation models in healthcare:
- How Foundation Models Can Advance AI in Healthcare
- “Flying in the Dark”: Hospital AI Tools Aren’t Well Documented
- How Do We Ensure that Healthcare AI is Useful?
Stanford HAI’s mission is to advance AI research, education, policy and practice to improve the human condition. Learn more