
A Moderate Proposal for Radically Better AI-powered Web Search

Advanced language models could overhaul how we search online. But scholars argue a constrained approach will return better results. | Tarik Kizilkaya
Web search is likely to change significantly over the next decade, as it incorporates recent advances in artificial intelligence, especially those relating to large neural language models like GPT-3.
In one vision of the future, we would replace the entire apparatus with a black-box model that directly answers any question you pose. No more scanning through search results, clicking on links, and then scrolling through pages. The search technology delivers the information you seek in natural language, like a tireless, all-knowing (or at least very confident) friend.
This sounds initially appealing, but we argue that it raises serious challenges relating to reliability and trust. Where is the system finding this information, and is it accurate?
We advocate instead for an alternative that combines the best aspects of current search technology with new developments in AI. This area of research is known as Neural Information Retrieval (IR), and we will highlight an approach centered around the ColBERT model (pronounced like the famous talk show host).
Our proposal is moderate in that it retains core aspects of the user experience of present-day Web search. However, we have extensive evidence that it can lead to radically better systems while maintaining trust and reliability.
Web Search is on the Cusp of Change
Web search is one of the great innovations in history. Information that was once essentially inaccessible can now be found in seconds, and no specialized skills are necessary – just type a simple natural language query and scan the ranked list of results for the information you seek. This is enabled by a massive index that associates terms in your query with ranked lists of documents and employs sophisticated algorithms to combine the results in multiple lists when your query has multiple terms. Figure 1 depicts this classical paradigm.
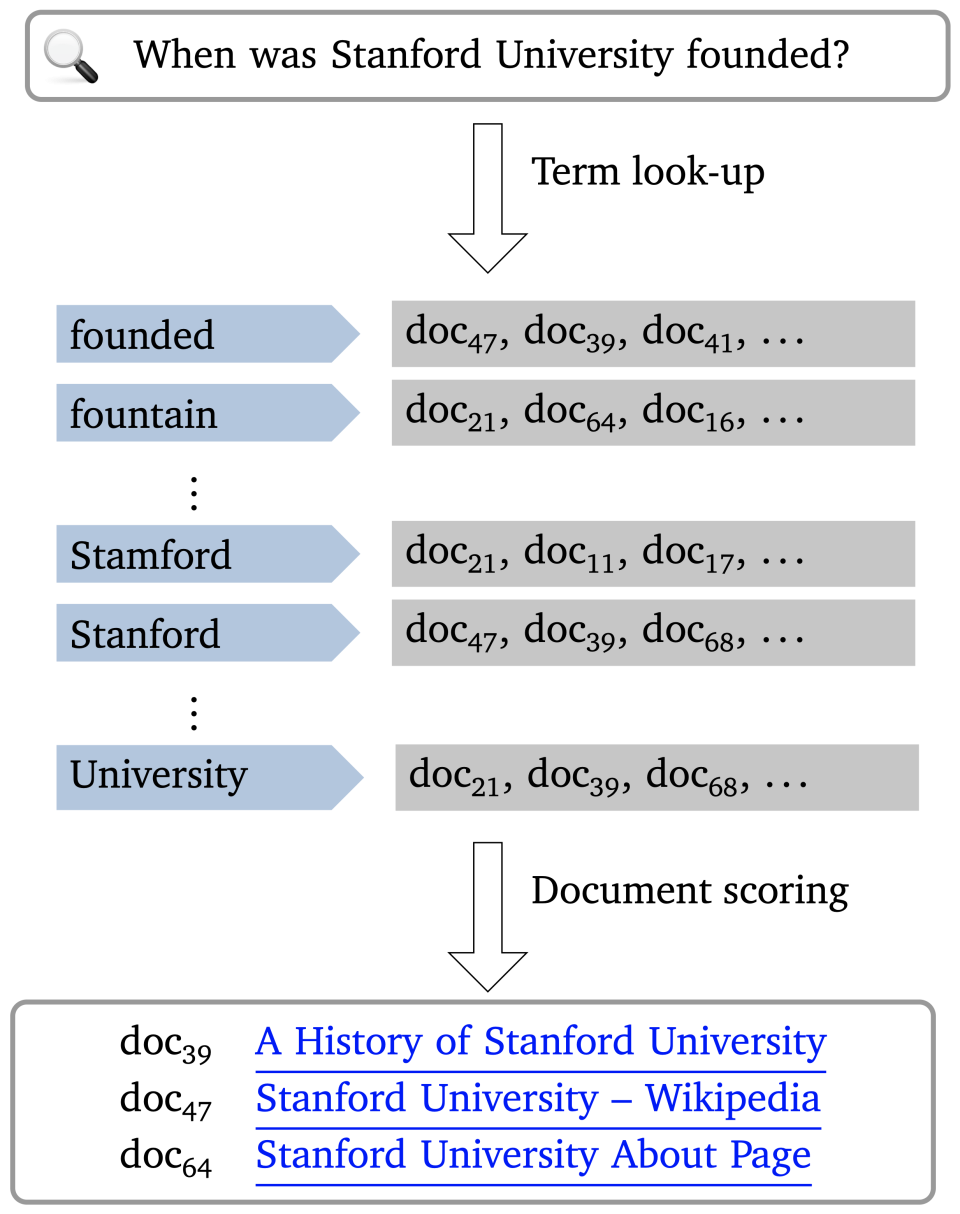
The classical search interface and paradigm: The user’s query keys into a massive mapping from terms to relevant documents (left), and specialized scoring algorithms turn these into lists of ranked linked documents for the user to go through (right).
Strikingly, while Web search results have continued to improve (perhaps with some added clutter from ads), the user experience and the underlying technological pieces both have remained fairly constant. However, we seem to be on the cusp of major change, brought on by advances in natural language processing (NLP) and AI.
Web Search as Question Answering
One radical proposal for change would go as follows: We replace the above reassuringly familiar search experience with a very different experience, one that is at once more human and more disorienting than what we are familiar with.
In this new approach, you would simply pose a natural language question, in text or in speech, and the technology would respond with a natural language answer. The response might synthesize information from various pages on the Web. No need for you to strategize about the best query terms or wade through lists of linked Web pages. You ask, and the system answers with what you need.
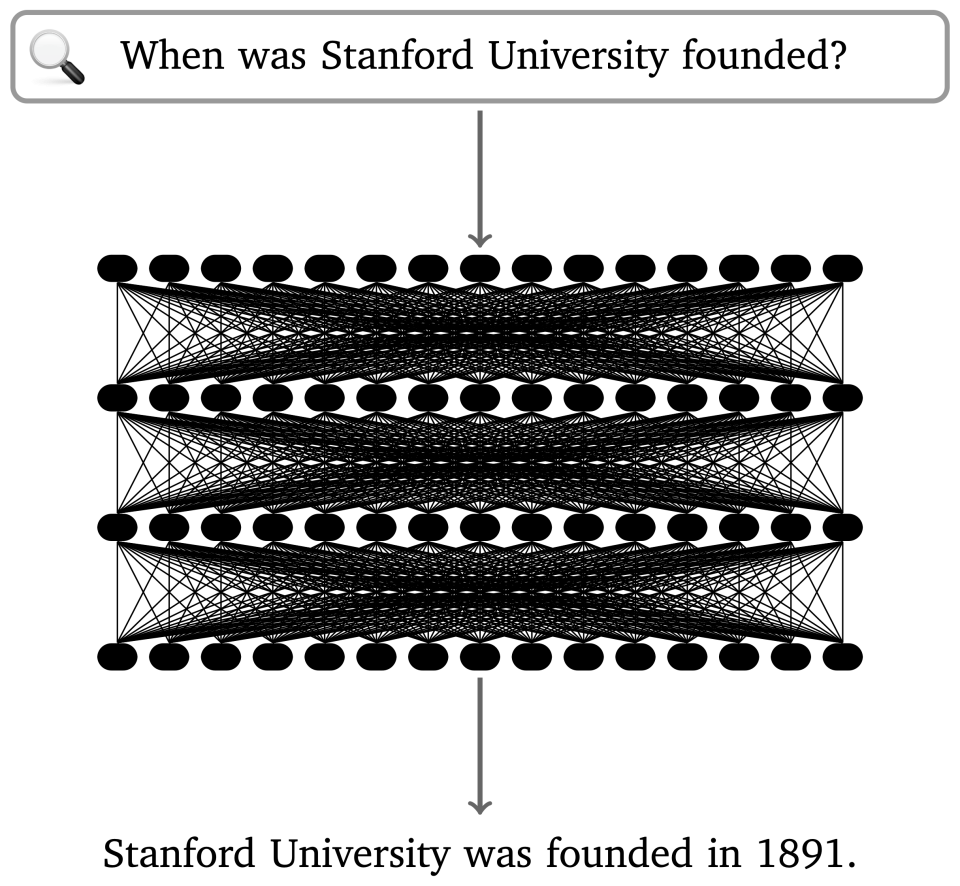
The classical search paradigm is replaced with one in which a “black box” neural language model, such as GPT-3, directly answers the user’s question. This approach exploits the vast capacity of neural language models to store information, and their ability to consume and produce natural language texts. In this case, though, the model is mistaken: Stanford was founded in 1885.
This approach is explored in Rethinking Search: Making Experts out of Dilettantes, from Donald Metzler, Yi Tay, Dara Bahri, and Marc Najork at Google Research. In an MIT Technology Review piece covering the work, we get a visionary summary of the position: “The problem is that even the best search engines today still respond with a list of pages that include the information asked for, not with the information itself.” Thus, in this view, our goal should be a system that simply provides the information. We ask questions, and, as the article says, “have a language model trained on those pages answer them directly.”
Neural Language Models as Search Technologies
Such a proposal was not really on the table until very recently. Before about 2018, technologies that could answer questions tended to be brittle, hard to build, and even harder to scale. The advent of neural language models changed that. These models can have enormous numbers of parameters – the field is pushing past 1 trillion right now – giving them an incredible capacity for storing information. They are trained on massive quantities of unstructured data and, in this way, acquire something like a capacity to understand that data.
The essence of proposals like the one in “Rethinking Search” is depicted in Figure 2: We replace the classical index mapping terms to documents with a language model that implicitly captures the information present in the documents on the Web, but synthesized in ways that enable direct answers to questions. If you want to know which year Stanford University was founded, you’ll just ask, and the system will respond, “1891.” No need to scan a list of search results, guess about which page will give a reliable answer, click a link, and read until you see the answer.
But, wait – is that correct? 1891? It doesn’t sound quite right. Now what? You could follow up by asking, “What is your source for this?” and perhaps the system will answer with the text “The Stanford University About page.” That might be helpful, but does the page really say that? What if the model had instead produced the text “Wikipedia” or “The Onion.” How would this information have affected your assessment of the value of the answer you got? And aren’t you just going to have to find and read these pages for yourself anyway? (We will save you the trouble in this case: Stanford was founded in 1885 but enrolled its first students in 1891.)
The Importance of Provenance
This example highlights a key feature of classical Web search that we tend to take for granted: provenance. Lists of relevance-ranked Web pages might not directly answer your question, but they reliably convey where specific information is coming from. You yourself can decide which sources to trust, and you can go directly to those sources for additional context. Metzler et al. also emphasize the importance of provenance for search.
Language models alone cannot easily track provenance. It is in their very nature to synthesize information and store it in an abstract format that does not preserve the structure of individual pages or their identities. Even if the model says that it got its answer from a specific page – even if it supplies a well-formed Web link in its answer – there is no reason to trust this information any more than you trust the answer itself.
Neural IR and the ColBERT Model
This is not to say that language models have no place in Web search. On the contrary, we think they can be extremely valuable. The key insight is that language models can be used to directly consume questions and generate answers, as above, but they can also be used as devices to represent data, and they are impressively good at this. Indeed, the most prominent role they play in NLP technologies is to convert natural language text to numerical vectors that can be used in numerical algorithms and that capture deep aspects of meaning.
This is the essence of Neural IR: Neural language models are used to process documents and queries into these abstract numerical representations, which replace the more superficial term-based representations used by older indexing systems. The result is a super-charged version of the classical search paradigm, one that can find deep semantic connections between queries and documents and also extract pieces of text as evidence for the pages it links to. Figure 3 summarizes this paradigm
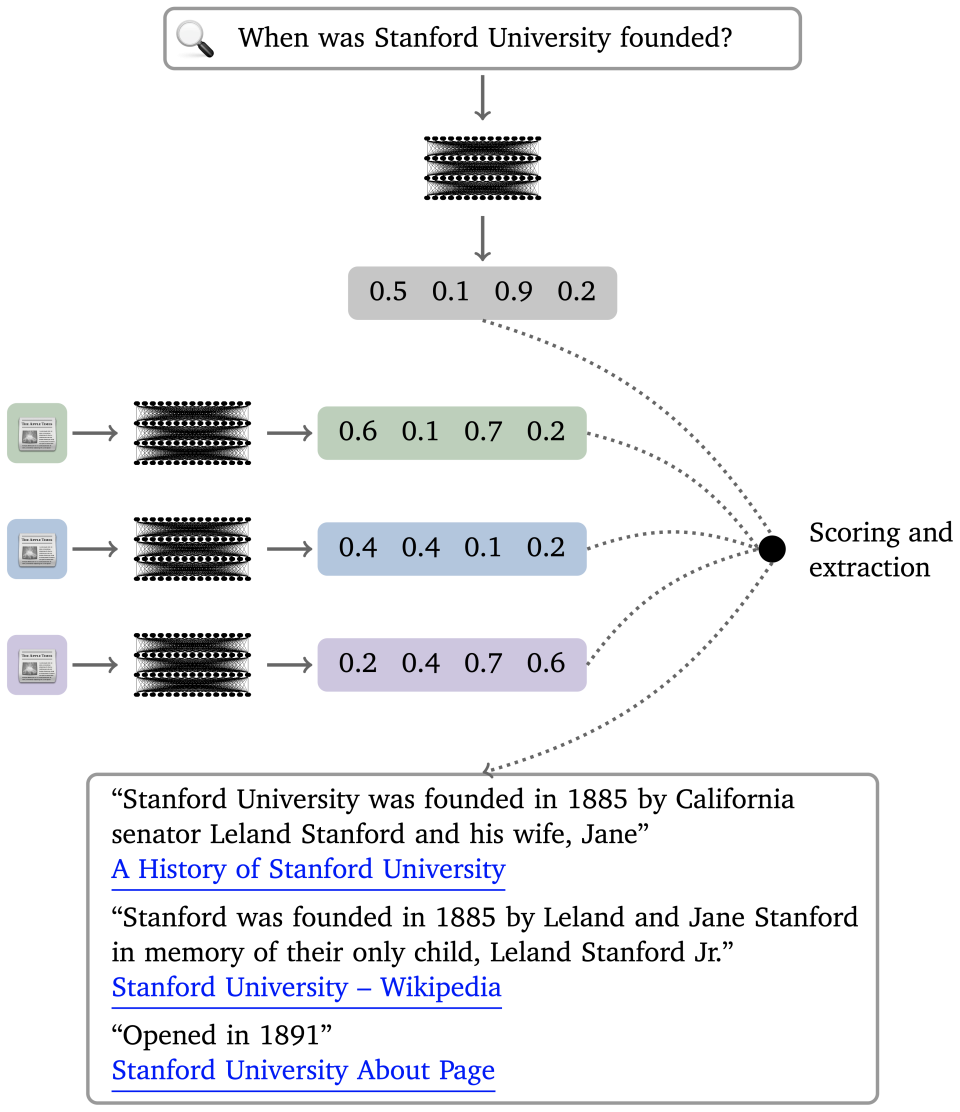
The core Neural IR paradigm. Documents and queries are encoded into numerical representations using a pretrained neural language model. A scoring function compares them to determine a ranked list of search results as in the classical paradigm, and an extraction function (possibly also based in a neural language model) identifies relevant text spans to offer as direct evidence.
In the Neural IR approach, complex queries (such as natural language questions) are interpreted more deeply than in the classical paradigm, and search results are dramatically better. Models can also highlight the most relevant text from documents and even combine excerpts directly from multiple sources. Crucially, though, these results are still attached to specific sources in a reliable fashion. Provenance is easy to trace, and the “trust but verify” model of classical Web search is not broken.
Neural IR is one of the most vibrant areas of research at the intersection of NLP and IR, and it is an area that is likely to very rapidly have an impact on the technology industry, since search functionality is central to organizations large and small. The field is brand new, but it has already booked very impressive results. In 2019, both Google and Microsoft announced that their search engines now employ Neural IR techniques, and the field has only continued to advance since.
The ColBERT model of Khattab & Zaharia 2020 has been central to our own research in this area. The “Col” in the name stands for Contextualized late interaction: The model captures fine-grained interactions between documents and search queries (the contextualized part), but these interactions are “late” in its data-processing to allow for fast search results and the sort of off-line processing that scales to massive document collections. The “BERT” part of the name refers to the famous BERT model of Devlin et al. 2019, which ColBERT uses as a pre-trained component.
Neural IR models like ColBERT are already beating tried-and-true search models by wide margins, and they can excel even in areas in which the direct Q&A approach in Figure 2 might seem to have the edge. For example, we noted above that some queries can only be resolved by combining information from multiple sources. The recent benchmark tasks HotpotQA and HoVer assess systems on such difficult cases. Suppose the query is “Which MVP of a game Red Flaherty umpired was elected to the Baseball Hall of Fame?” At present, this requires three Wikipedia pages to answer. A black box neural model might be able to generate the response “Sandy Koufax,” but how will you verify this without having to hunt down pages pertaining to Flaherty, Koufax, or perhaps the Baseball Hall of Fame yourself?
Our Neural IR proposal can be designed to synthesize original responses too, but we can bring in context, because all information is ultimately extracted from specific Web pages. Our response might look more like this: “Sandy Koufax, elected to the Hall of Fame in 1972 [link], was the MVP of the 1965 World Series [link], where Red Flaherty was an umpire [link].” Provenance is tracked – down to the sentence level – even for synthesized responses.
Neural IR systems are succeeding at these challenging tasks in practice. For example, our Baleen system, which uses a flavor of ColBERT as a central component, recently improved the accuracy score on HoVer from 15% to 57%.
Changing Results for a Changing World
Provenance is not the only serious problem that comes from replacing Web search with a language model. As the world changes, a language model serving as a free-standing Web search technology will need to change with it. Such models do not support targeted updates, so they will have to be constantly retrained to reflect new facts. Training such a model is extremely costly. For example, training GPT-3 likely cost more than US $10 million and took months. The environmental impact of such processes is also significant. Even if we find ways to reduce these costs, it will remain true that having to retrain a large model in order to update results is incredibly inefficient.
We might also consider the issue of removing information. Technology companies might need to quickly remove pages because they contain offensive or misleading content, or because users have a right to request such removals. This is all manageable with standard Web technologies, where one can remove documents from an index, but it is infeasible with a neural language model. There is no reliable way to remove specific information from language models – this is a direct consequence of the way they store information. Applying simple keyword filters on their outputs is not a panacea, as these models might still find ways of expressing the same content in new terms.
The more modest use of language models that characterize Neural IR suffer none of these drawbacks. Individual pages can be added and removed from the index as before. For example, when the Wikipedia page for “President of the United States” is updated after an election, we simply use our language model to compute the representation of the new page and update the index entry. This can be done in just a few milliseconds of compute time, without the massive cost of retraining or updating a language model.
Moving Forward
Research at the intersection of NLP and IR is proceeding at an incredible pace, and it is an area with the potential to have enormous consequences for technology and, in turn, for society. Neural language models are a driving force in these developments. We argued above for a fairly conservative application of these models – conservative in the sense that it retains familiar aspects of Web search. The central insight here is that language models are not, and will never be, all-knowing infallible oracles, even if they seem to behave that way when you ask them questions. Recent Neural IR methods like ColBERT and Baleen use these models carefully and strategically to improve search results while preserving trust and reliability.
Omar Khattab is a Computer Science Ph.D. student at Stanford University; Christopher Potts is professor and chair of the Department of Linguistics in the Stanford School of Humanities and Sciences, as well as a professor by courtesy of Computer Science in the School of Engineering; Matei Zaharia is an assistant professor of Computer Science.
Stanford HAI's mission is to advance AI research, education, policy and practice to improve the human condition. Learn more.