
The Time Is Now to Develop Community Norms for the Release of Foundation Models

As foundation models (e.g., GPT-3, PaLM, DALL-E 2) become more powerful and ubiquitous, the issue of responsible release becomes critically important. In this blog post, we use the term release to mean research access: foundation model developers making assets such as data, code, and models accessible to external researchers. Deploying to users for testing and collecting feedback (Ouyang et al. 2022; Scheurer et al. 2022AI Test Kitchen) and deploying to end users in products (Schwartz et al. 2022) are other forms of release that are out of scope for this blog post.
Foundation model developers presently take divergent positions on the topic of release and research access. For example, EleutherAI, Meta, and the BigScience project led by Hugging Face embrace broadly open release (see EleutherAI’s statement and Meta’s recent release). In contrast, OpenAI advocates for a staged release and currently provides the general public with only API access; Microsoft also provides API access, but to a restricted set of academic researchers. Finally, for their largest foundation models, Google and DeepMind have only released papers (Google’s PaLM, DeepMind’s Gopher).
While we do not expect consensus, we believe it is problematic for each foundation model developer to determine its release policy independently. There are two reasons for this. First, a single actor releasing an unsafe, powerful technology could cause significant harm to individuals and society. Even if one judges the risks of today’s foundation models not severe enough to justify limits on a relatively open release, the rapid pace of development creates considerable uncertainty about the capabilities of future models. So we believe caution is warranted. Second, precisely because the severity of the risks of foundation models are unclear, foundation model developers would benefit greatly from sharing best practices, rather than each organization reinventing the wheel and incurring the economic and social costs of rediscovering certain harms. Moreover, increased collaboration and transparency can address the collective action problem of organizations generally underinvesting in responsible AI due to strong economic incentives to move quickly (Askell et al. 2019). The bottom line is that we need community norms that govern the release of foundation models, especially as the technology becomes more powerful.
Tension between the benefits and risks of release. Since foundation models can be adapted to myriad downstream applications, no organization can fully anticipate all potential risks (or foresee all potential benefits). Consequently, it is imperative that external researchers representing a diversity of institutions, cultures, demographic groups, languages, and disciplines be able to critically examine foundation models from different perspectives (Raji and Buolamwini, 2019; Raji et al. 2020; Metaxa et al. 2021). This is made easier with a broad release. At the same time, a broad release, even if targeted towards researchers, could enable some entity to gain access and deploy without the necessary safeguards and cause harm (Bender and Gebru et al. 2021; Weidinger et al. 2021; Buchanan et al. 2021), intentionally or not.

Figure 1. A simplified view of the tradeoff between no release, which can increase control over immediate risks, and fully open release, which allows for a better understanding of risks in the long run.
Release therefore introduces a tension between (i) the open production of scientific knowledge, including knowledge of the limitations and risks of foundation models and (ii) the risks of unsafe deployments made possible by release. While it is impossible to fully resolve this tension, we can make some progress by going beyond the simplistic one-dimensional view and exploring a richer design space of release policies.
A Framework for Release
As Sastry (2021) has argued, release is not a binary decision; rather, “there may be a vast and underexplored design space of release options.” We provide a coordinate system for this design space by identifying four key questions: what to release, to whom to release, when to release, and how to release.
What: There are many assets related to a foundation model that could be released, such as papers, models, code, and data, each with its own impact on both expanding scientific knowledge and increasing the potential risk of harm. We could place these assets on a spectrum corresponding to the strength of release, but let us refine this view by first grouping these assets into direct and indirect assets.
Direct assets provide access to an existing model, which both allows for the immediate study of the model and could enable the deployment of the model, even if such use is prohibited by the terms of use. Forms of direct access include (i) developer-mediated access (e.g., to predictions or embeddings), (ii) API access, and (iii) access to model weights. Currently, API access is the most common, and is a form of structured access (Shevlane, 2022), which enables monitoring and revocation of access. Developer-mediated access (i.e., having the foundation model developer run an evaluation on behalf of an external researcher) provides even stronger oversight and reduces the infrastructural cost of maintaining an API, but introduces a human bottleneck and cannot support research that requires interactivity. In the other direction, access to model weights supports deeper research that is not possible even with API access, such as developing novel fine-tuning methods. Note that access to model weights does not preclude structured access: model weights could be hosted on a developer-controlled environment, which would provide developers with oversight and researchers with the convenience of the provided compute resources.
Indirect assets provide the means to build a model; these include (i) a paper describing the foundation model, including details about data, training, and the model; (ii) access to the code for training and data processing; (iii) access to the training data (which is rare); and (iv) computation resources to train new models (which are significant). It is worth noting that publishing a paper is a form of release. If a paper contains enough detail to reproduce the model, then releasing that paper could be the functional equivalent of releasing the full model in terms of enabling use (and more concerningly, misuse) by highly-resourced actors (Leahy, 2021). But in practice, a paper is insufficient for full reproducibility (see Meta’s logbook for a taste), and a stronger release in the form of the code, data, and compute (e.g., via cloud credits) are needed. If released responsibly, these assets would open up vast new opportunities for research, including exploring new model architectures, exploring new training strategies, and performing data ablations. We believe that this type of research access (notably compute) is essential for making fundamental long-term improvements to foundation models.
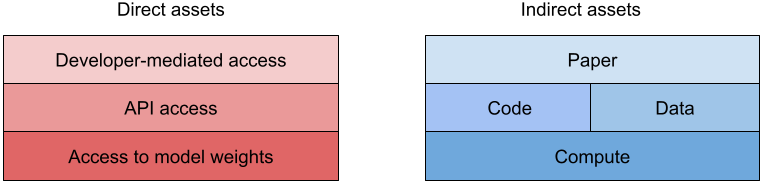
Figure 2. A foundation model developer can release direct assets, which provide the means to use an existing foundation model; and indirect assets, which provide the means to understand the construction of an existing model or build a new model.
To whom: In other arenas such as the dissemination of scientific papers or deployment of products, it is customary to divide the external population into rings (Humble, 2016), where the inner ring consists of colleagues (greater trust) and the outer ring consists of the general public (greater diversity). It is natural to consider analogous rings for foundation models: (i) colleagues that the foundation model developer knows and trusts, (ii) those who apply for access based on a public call that are then granted access by the developer, and (ii) the general public. The middle ring is particularly important, and we will return to it.
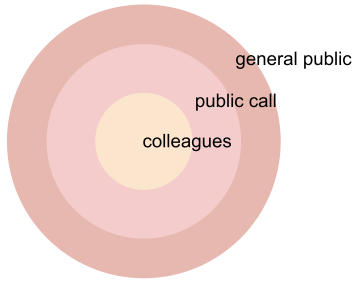
Figure 3. A foundation model developer in general will release assets gradually, starting with hand-picked trusted colleagues, those approved based on a public call, and finally the general public.
When: When an asset should be released depends on both intrinsic properties, such as the results of safety evaluations, and external conditions, such as what other models exist and how much time has elapsed. In general, we believe that release should proceed in stages (Solaiman et al. 2019), where each stage broadens along the what or to whom axis. Critically, we believe this progression should be gated by conditions: for example, to expand access to the general public, some temporal interval should have elapsed to allow time for analysis and the model should pass a certain safety standard.
How: Beyond staging, we believe that release should not be a one-time decision. Foundation model developers have the responsibility for maintaining their release over time, akin to maintaining software (Raffel, 2021). Release should include a bidirectional means for communication between developers and researchers. If downstream users have feedback, such as specific failure cases or systematic biases, they should be able to publicly report these to the developer, akin to filing software bug reports. Conversely, if a model developer updates or deprecates a model, they should notify all downstream users.
The Foundation Models Review Board
To make better-informed release decisions with input from the broader community, we propose creating a foundation models review board. The goal of the board is to facilitate the process of foundation model developers releasing foundation models to external researchers. Such release broadens the set of researchers who can study and improve foundation models while managing the risks of release.
Incentives. For the review board to be effective, there must be strong incentives for all stakeholders to participate, including foundation model developers, researchers, and board members. From a foundation model developer’s perspective, the board would serve as a trusted entity that can provide feedback about release and best practices. The board would also provide a structured mechanism to request help from external researchers, and it would relieve the developer of the sole responsibility for determining release standards and processes. From a researcher’s perspective, the board serves as a portal to gain access to foundation models as well as a way to obtain feedback about how to conduct research with foundation models responsibly. It would also help bridge the gap between the problems studied in the research community and those encountered in developing and deploying these models. Finally, from the general public’s perspective, the board would broaden access to foundation models in a responsible way, increase collaboration and coordination between foundation model developers and external researchers, and increase transparency.
The review board naturally is rooted in reviewing, an established mechanism for producing better outcomes in research. Traditional examples include peer reviewing in conferences and reviewing research proposals for funding. More recent examples motivated by the growing social impacts of AI research include the Ethics & Society Review Board (ESR; Bernstein et al. 2021) and the recent NeurIPS ethics review process. We can lean heavily on our experiences with these processes to figure out how to best manage reviewer load, ensure reviewer quality, and maintain impartiality.
The basic workflow of the review board is as follows:
-
A developer posts a call for proposals (similar to the one for the Microsoft Turing Academic Program) describing what foundation model(s) are available and what the developer believes to be the most critical areas of research on these models.
-
A researcher submits a research proposal specifying the research goals, the type of access needed to accomplish those goals, and a plan for managing any ethical and security risks.
-
The board (which includes the foundation developer and other reviewers on the board) reviews the research proposal and deliberates, potentially with additional input from the researcher.
-
Based on the board’s recommendation, the foundation model developer makes a final decision to approve, reject, or defer the proposal.
-
If the proposal is approved, the foundation model developer releases the desired assets to the researcher.
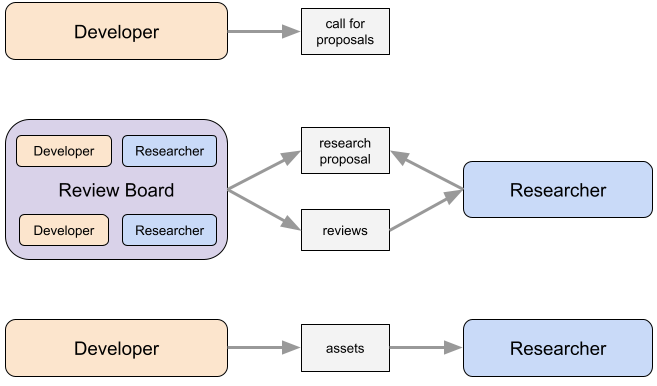
Figure 4. The foundation models review board operates as follows: A foundation model developer first puts out a call for proposals. Then an external researcher submits a proposal to the review board, which includes both the foundation model developer as well as other parties. The board reviews the proposal and produces a recommendation to accept, reject, or defer the proposal. Finally, the foundation model developer makes a decision based on the recommendation and releases assets to the researcher if the proposal is accepted.
The crucial aspect of the review board is that release decisions are made in a highly contextual way, for a particular researcher for a particular purpose, for a particular foundation model with a particular form of access, and at a particular point in time. This bottom-up concreteness makes it much easier to reason about the benefits and risks of a particular decision. The community norms on release then emerge through a series of these decisions.
Let us now sketch out what a review board might look like and discuss the various design decisions. We acknowledge that designing an effective review board is challenging, and it will require experimentation and more discussion with the community beyond this blog post.
Board composition. Since the purpose of the board is to develop and sustain community norms, the board’s composition is especially important. First, the board should be knowledgeable about the technical capabilities and limitations of foundation models, and about the social and ethical impacts of technology. Second, the board should be representative of the broader community, which includes members from academia, industry, civil society, as well as broad representation across institutions and demographic groups. Third, the board should be legitimate; if it were dominated by foundation model developers, it would be unlikely to gain public trust (and rightfully so). On the other hand, a body that excluded foundation model developers might be less effective in producing action and could become untethered to reality. We must therefore seek a pragmatic balance.
Research proposal. A researcher seeking access to a foundation model submits a research proposal explaining the goals of the research (e.g., understanding bias, investigating memorization, etc.), why the research is important, and what would be learned if the research were successful. Any preliminary results on smaller foundation models would strengthen the proposal (in a few cases, the project might be complete and all that is desired is running the same evaluation on a more powerful foundation model). Importantly, the proposal should indicate the type of access (along with a compute budget) is required to conduct the research. The proposal should also contain an ethics statement describing potential harms of the research and how the researcher plans to mitigate them. Any related proposals (e.g., the same proposal submitted to another foundation model developer) should be linked so that reviewers can coordinate on their decisions. To keep the review process lightweight, we recommend keeping the proposal short (e.g., 2-3 pages), but allowing for subsequent interactive researcher-reviewer discussion.
Reviewing. When the board receives a proposal, the board chairs assigns it to at least three reviewers (members of the board), including the foundation model developer. Each reviewer judges the proposal based on the scientific merit of the proposed idea, the (subjective) importance (safety and bias issues may be prioritized), and how robust the ethical statement is. The review might pose additional questions to the researcher, who can respond interactively, a mechanism that has been adopted in machine learning conferences such as ICLR and NeurIPS using OpenReview to avoid misunderstanding. Some negotiation about the type of access might ensue, and the proposal might be revised accordingly. The board chairs then summarize the reviews and make a recommendation to approve, reject, or defer the proposal. Finally, the foundation model developer makes a final decision. This decision could deviate from the board recommendation, but this fact would be transparent to the wider community. And collective deliberation of the reviewers could surface new information that we expect would flip the foundation model developer’s initial decision in some cases. In the end, we believe this process allows each foundation model developer to make a more well-informed decision.
Accountability. Transparency is an effective tool to make the board publicly accountable, though we note that transparency must be tempered by the need for confidentiality. There are a whole host of questions concerning this tradeoff which have been debated at length for conference reviewing: Should the proposals, reviews, decisions be public? Should the identities of the researchers and reviewers be public or at least visible to each other? These are questions that the board should answer, but in general, our recommendation is a default expectation of transparency absent compelling reasons for confidentiality.
There are clearly many details to be figured out, and the success of the review board, and thus the prospect of responsibly broadening research access to foundation models, will ultimately hinge on the careful execution of these details. We are in favor of starting small, staying concrete, being pragmatic, and taking action. There are many stakeholders with different incentives, and we must somehow align these incentives, for in the end, there is much common ground: we are all invested in the responsible development of foundation models.
Final Remarks
Let us zoom back out. Releasing foundation models is important since no single organization has the needed range of diverse perspectives to foresee all the long-term issues, but at the same time, release must be appropriately gated to minimize risks. The community currently lacks norms on release. Our emphasis here is that the question is not what a good release policy is, but how the community should decide. We have sketched out the foundation models review board with the intention of bringing together foundation model developers and researchers who would benefit from release and providing a constructive forum for discussing and debating the benefits and risks.
In AI research, we tend to celebrate norms of transparency and openness. These are important and long-standing values that have been particularly instrumental in the recent progress in AI. We also celebrate the democratization of AI, which is sometimes taken to mean that anyone should be able to have access to AI. However, democracy is not just about transparency and openness. It is an institutional design for collective governance, marked by fair procedures and aspiring toward superior outcomes. It is in this latter sense that we call for the democratization of foundation models. The proposed review board is an attempt to take seriously the idea of democracy as a form of collective decision making and governance.
Foundation models are rapidly evolving: the models in five years may be unrecognizable to us today, much like the models today would be inconceivable five years ago. Therefore, we must make decisions today not based on what exists but what could exist in the future. Even if releasing all foundation models publicly were acceptable today, it may not be in the future. Even if any one organization could anticipate the majority of risks today and be incentivized to repair them, their abilities and commitments may change in the future. Given the immense uncertainty and our poor ability to forecast the future, we cannot make decisions solely based on anticipated outcomes. Therefore, we need to focus on developing a resilient process that will allow us to be prepared for whatever lies ahead.
Acknowledgements
We are indebted to Michael Bernstein, Stella Biderman, Miles Brundage, Jack Clark, Jeff Dean, Ellie Evans, Iason Gabriel, Deep Ganguli, Daniel Ho, Eric Horvitz, Yacine Jernite, Douwe Kiela, Fei-Fei Li, Shana Lynch, Chris Manning, Vanessa Parli, Stacy Peña, Cooper Raterink, Toby Shevlane, Irene Solaiman, Alex Tamkin, Laura Weidinger, and Susan Zhang for their extremely insightful and thoughtful feedback. We have learned so much from our conversations with them, and this blog post has improved significantly with their input.
This story was first published on the Center for Research on Foundation Models blog. Stanford HAI's mission is to advance AI research, education, policy, and practice to improve the human condition.