Get the latest news, advances in research, policy work, and education program updates from HAI in your inbox weekly.
Sign Up For Latest News
Last year’s AI Index highlighted the lack of standardized RAI benchmarks for LLMs. While this issue persists, new benchmarks such as HELM Safety and AIR-Bench help to fill this gap.
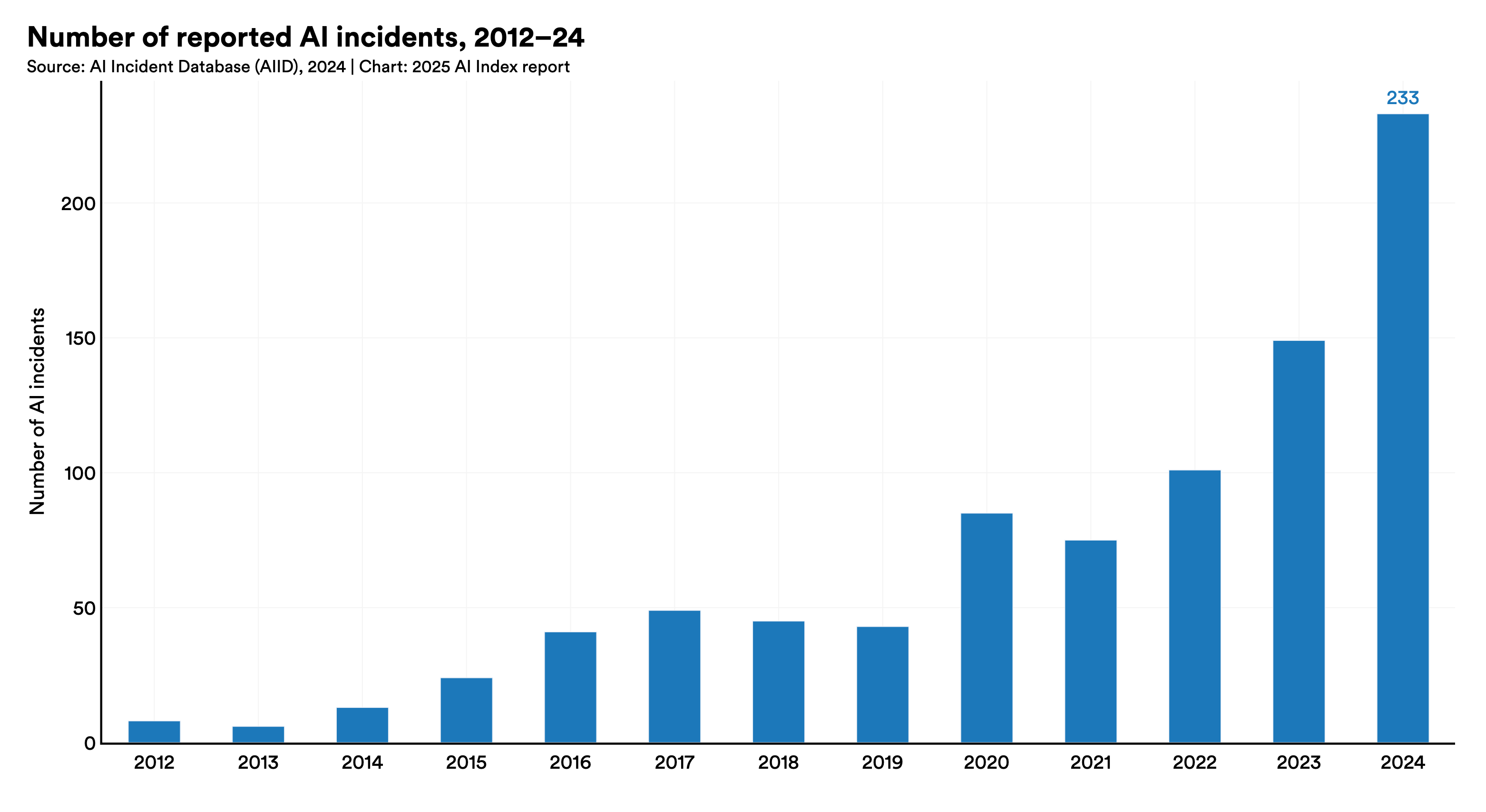
According to the AI Incidents Database, the number of reported AI-related incidents rose to 233 in 2024—a record high and a 56.4% increase over 2023.
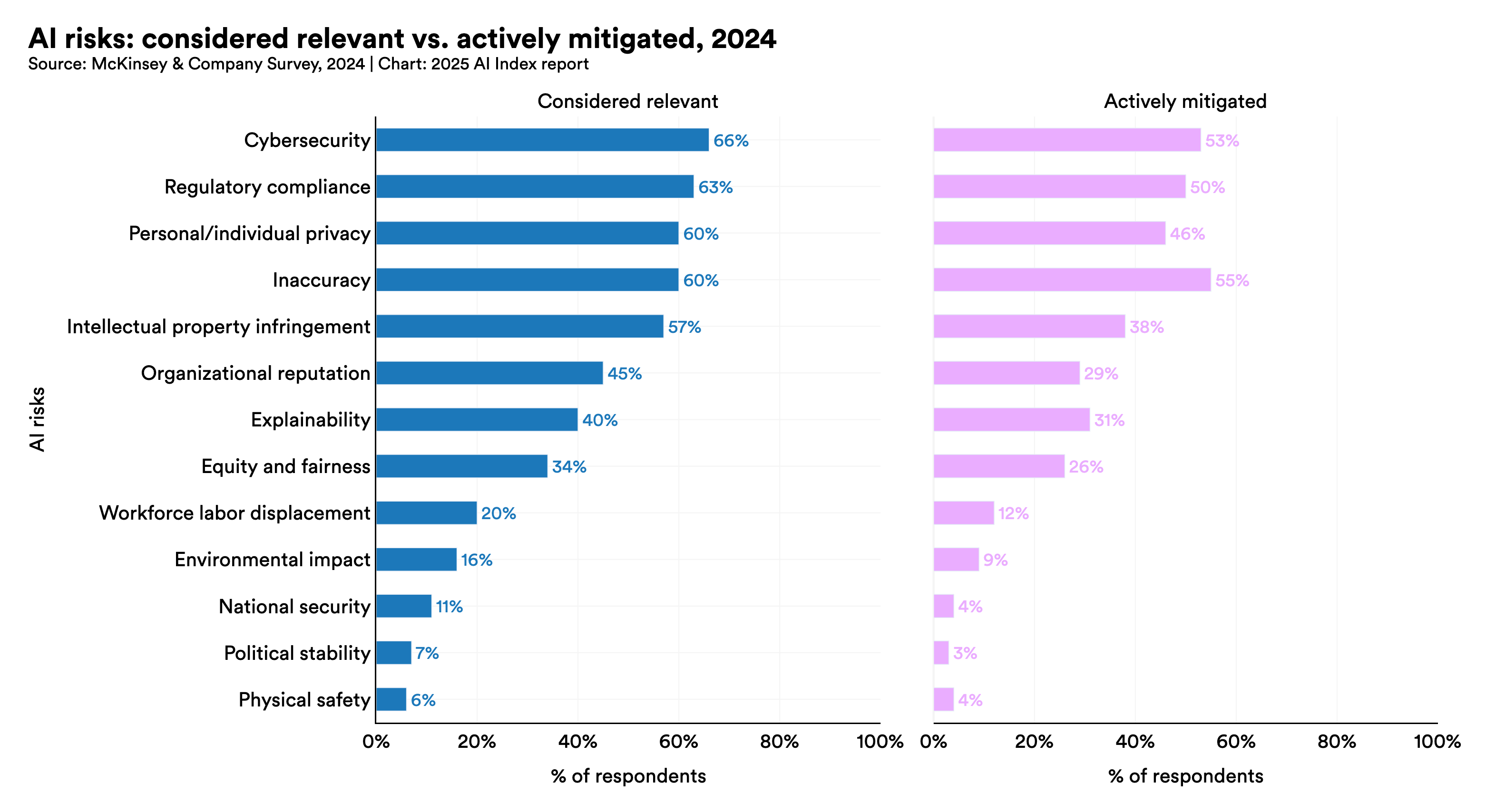
A McKinsey survey on organizations’ RAI engagement shows that while many identify key RAI risks, not all are taking active steps to address them. Risks including inaccuracy, regulatory compliance, and cybersecurity were top of mind for leaders with only 64%, 63%, and 60% of respondents, respectively, citing them as concerns.
In 2024, global cooperation on AI governance intensified, with a focus on articulating agreed-upon principles for responsible AI. Several major organizations—including the OECD, European Union, United Nations, and African Union—published frameworks to articulate key RAI concerns such as transparency and explainability, and trustworthiness.
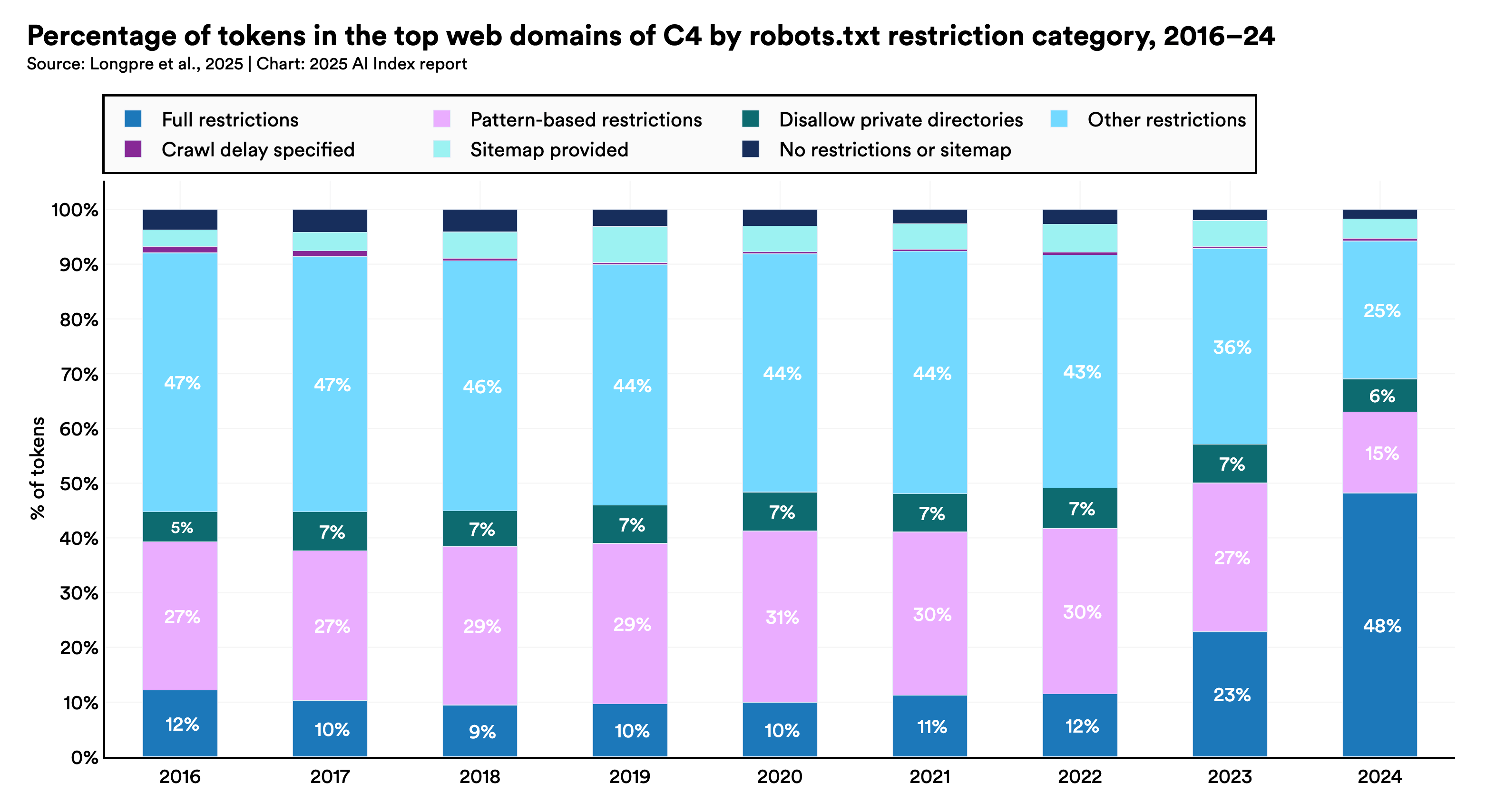
AI models rely on massive amounts of publicly available web data for training. A recent study found that data use restrictions increased significantly from 2023 to 2024, as many websites implemented new protocols to curb data-scraping for AI training. In actively maintained domains in the C4 common crawl dataset, the proportion of restricted tokens jumped from 5–7% to 20–33%. This decline has consequences for data diversity, model alignment, and scalability, and may also lead to new approaches to learning with data constraints.
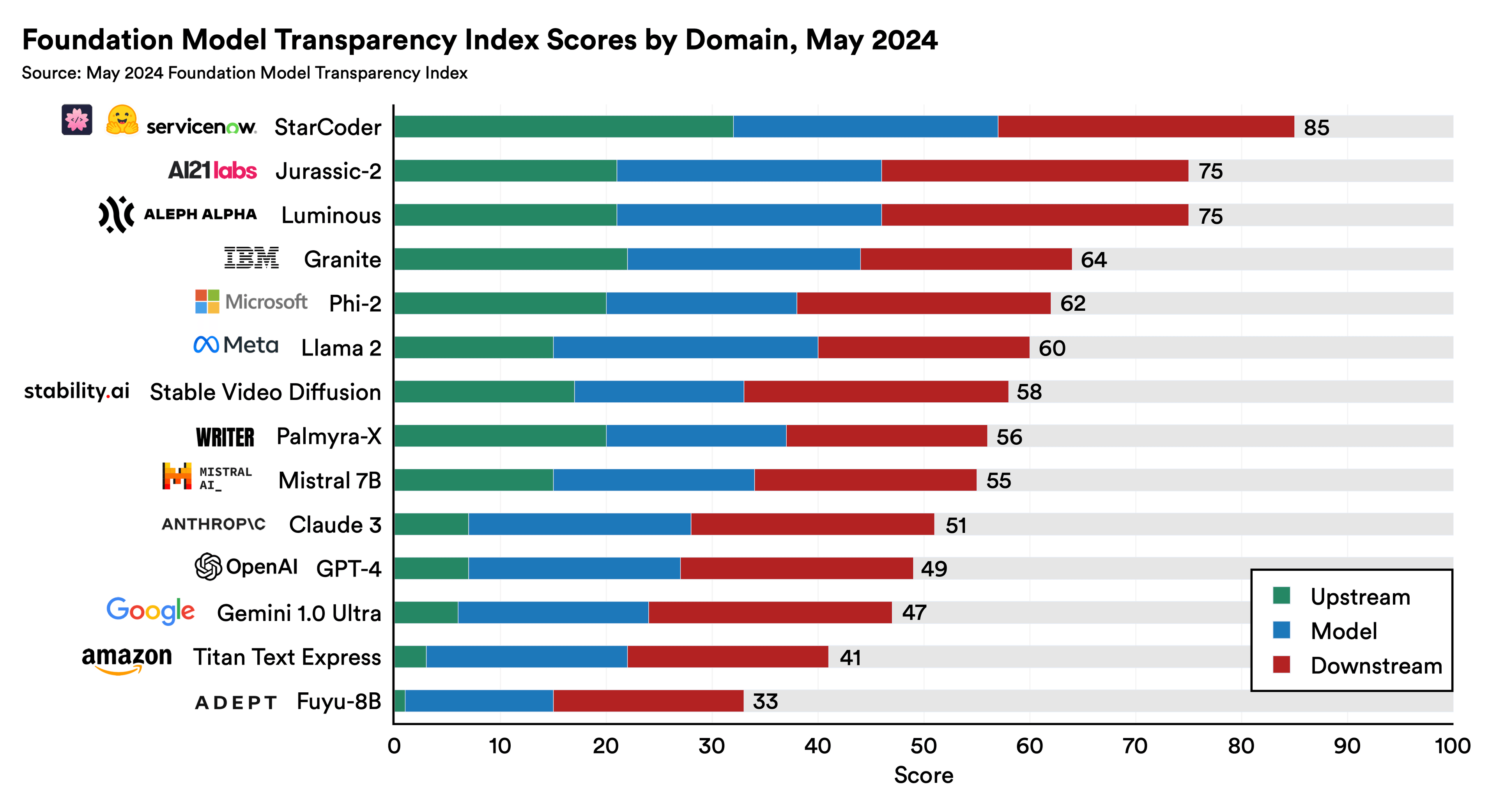
The updated Foundation Model Transparency Index—a project tracking transparency in the foundation model ecosystem—revealed that the average transparency score among major model developers increased from 37% in October 2023 to 58% in May 2024. While these gains are promising, there is still considerable room for improvement.
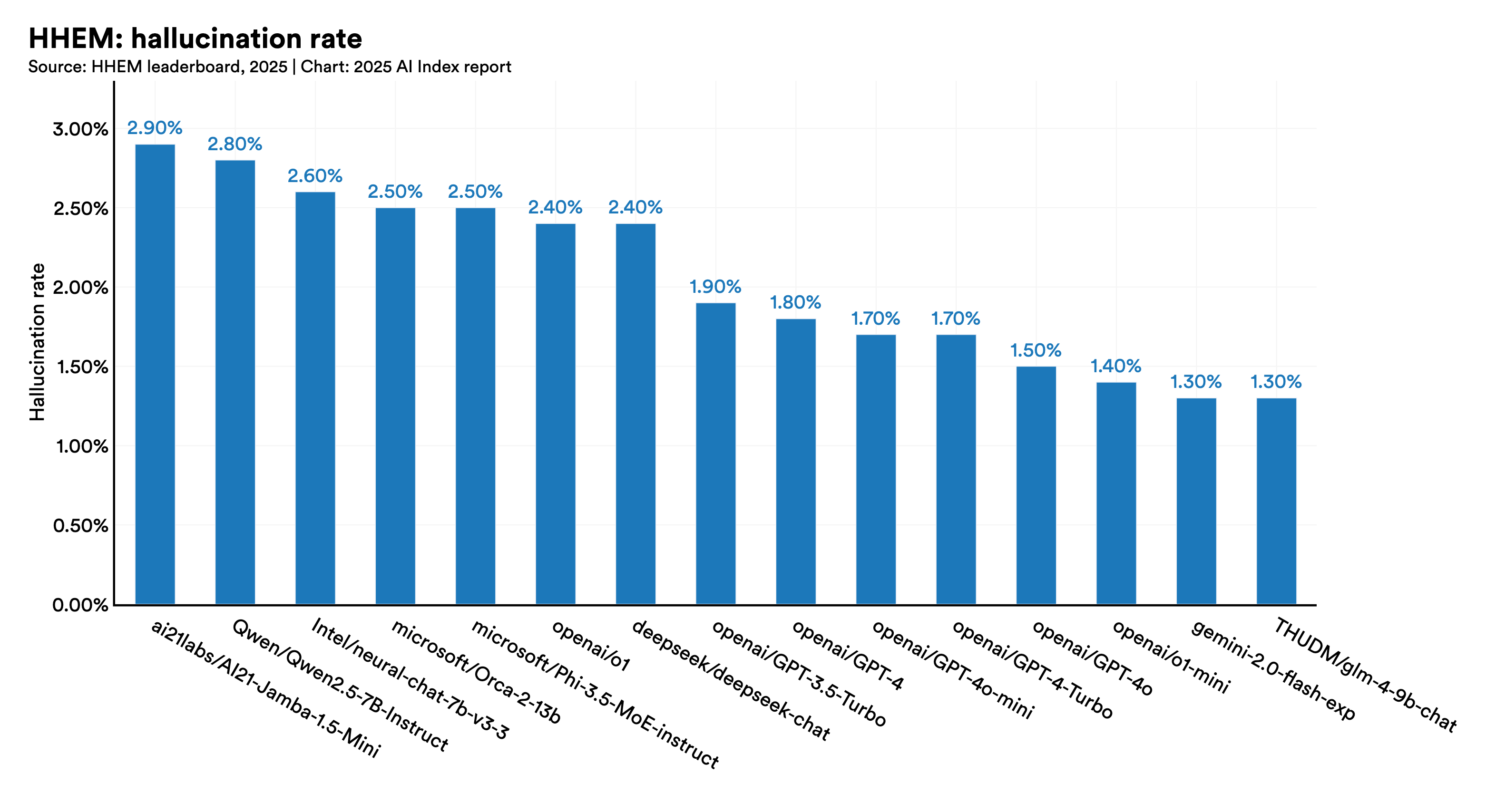
Earlier benchmarks like HaluEval and TruthfulQA, aimed at evaluating the factuality and truthfulness of AI models, have failed to gain widespread adoption within the AI community. In response, newer and more comprehensive evaluations have emerged, such as the updated Hughes Hallucination Evaluation Model leaderboard, FACTS, and SimpleQA.
In 2024, numerous examples of AI-related election misinformation emerged in more than a dozen countries and across over 10 social media platforms, including during the U.S. presidential election. However, questions remain about measurable impacts of this problem, with many expecting misinformation campaigns to have affected elections more profoundly than they did.
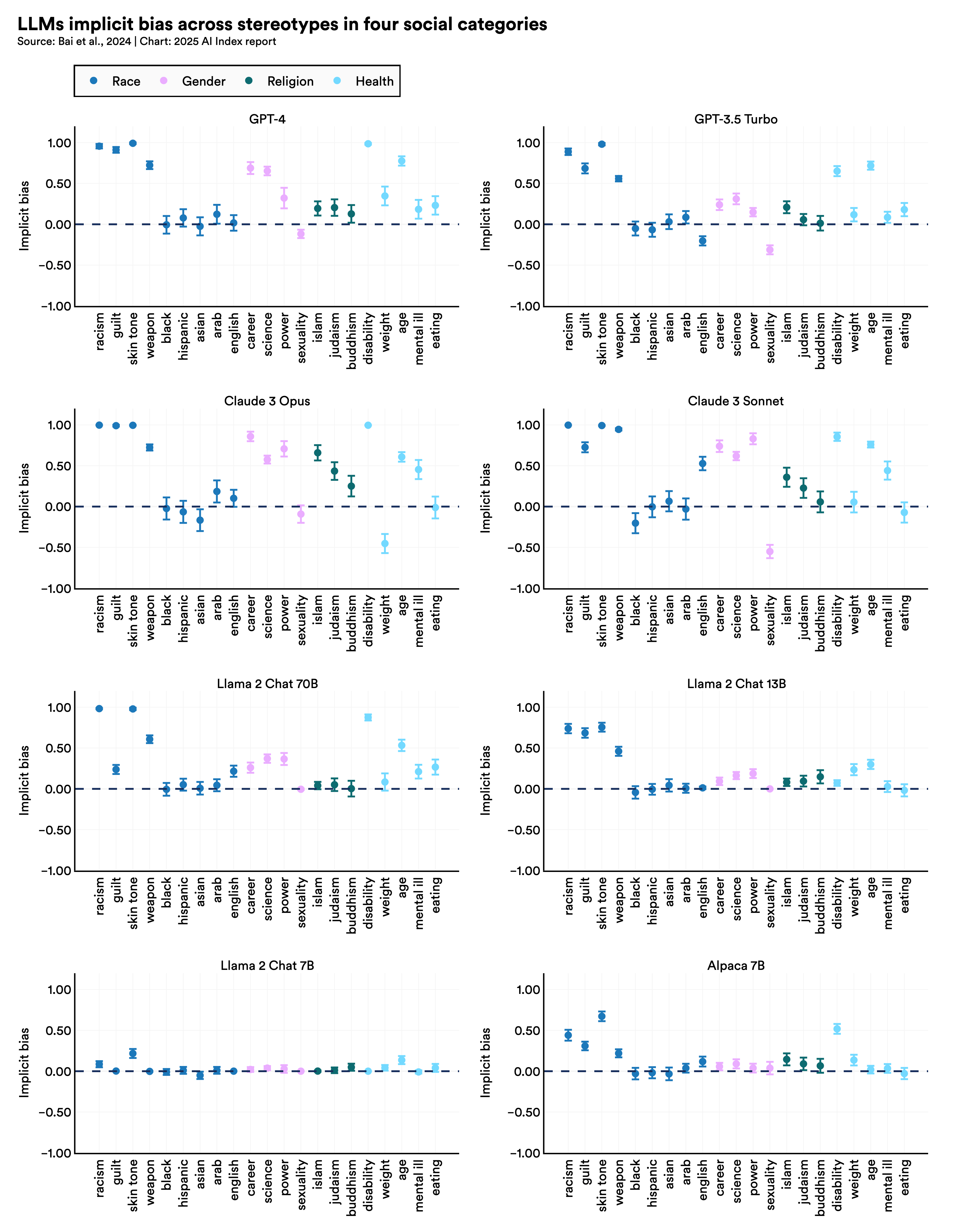
Many advanced LLMs—including GPT-4 and Claude 3 Sonnet—were designed with measures to curb explicit biases, but they continue to exhibit implicit ones. The models disproportionately associate negative terms with Black individuals, more often associate women with humanities instead of STEM fields, and favor men for leadership roles, reinforcing racial and gender biases in decision-making. Although bias metrics have improved on standard benchmarks, AI model bias remains a pervasive issue.
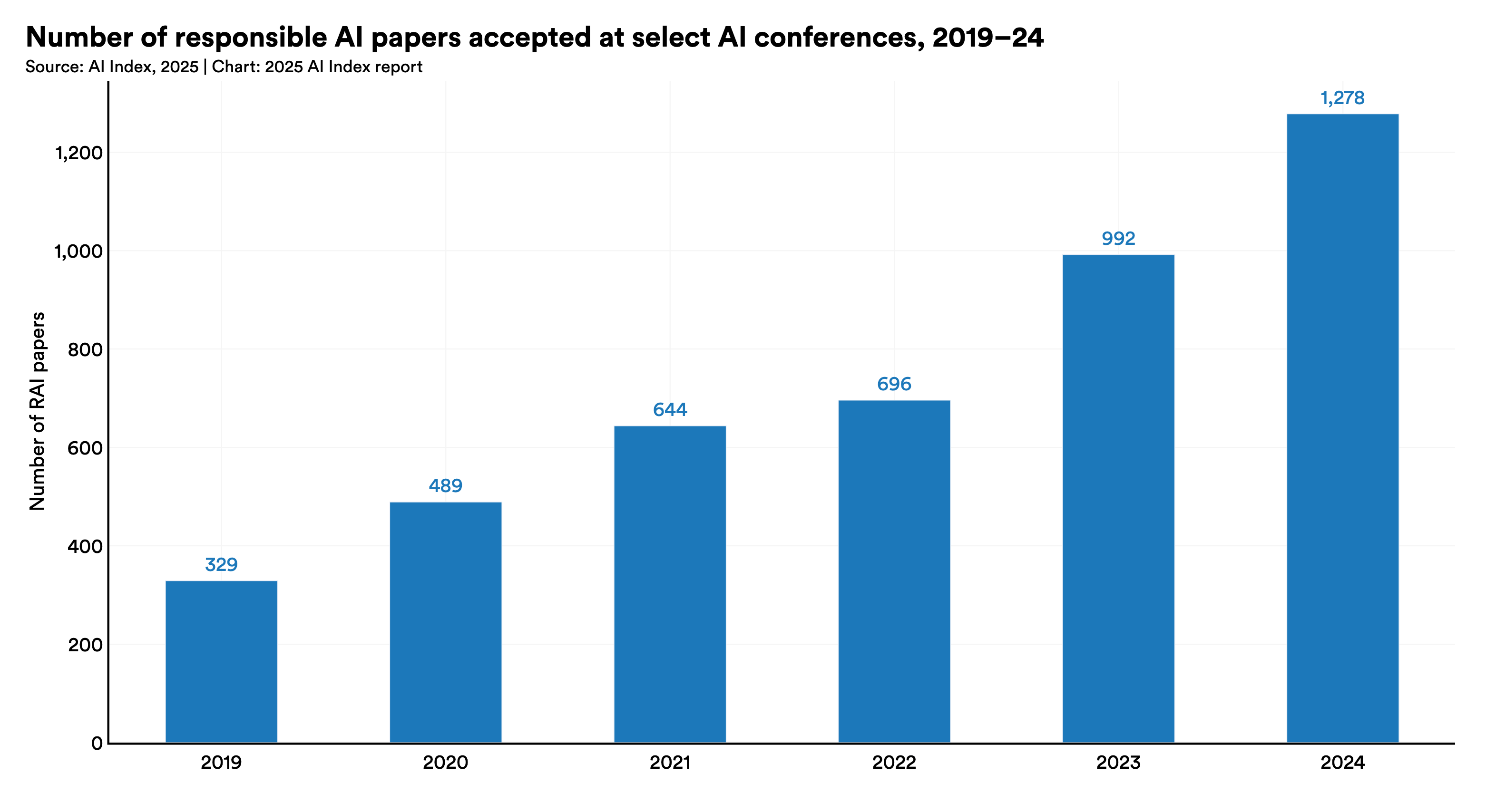
The number of RAI papers accepted at leading AI conferences increased by 28.8%, from 992 in 2023 to 1,278 in 2024, continuing a steady annual rise since 2019. This upward trend highlights the growing importance of RAI within the AI research community.