Examining Emergent Abilities in Large Language Models
Scholars track how models change with scale.
Much of the research in artificial intelligence in the past two decades has focused on training neural networks to perform a single specific task (e.g., classifying whether an image contains a cat, summarizing a news article, translating from English to Swahili) given labeled training data for that task. In recent years, a new paradigm has evolved around language models — neural networks that simply predict the next words in a sentence given the prior words in the sentence.
After being trained on a large unlabeled corpus of text using this objective, language models can be "prompted" to perform arbitrary tasks framed as next word prediction. For instance, the task of translating an English phrase into Swahili could be reframed as next-word prediction: "The Swahili translation of 'artificial intelligence' is ..."
This new paradigm represents a shift from task-specific models, trained to do a single task, to task-general models, which can perform many tasks. Task-general models can even perform new tasks that were not explicitly included in their training data. For instance, GPT-3 showed that language models could successfully multiply two-digit numbers, even though they were not explicitly trained to do so. However, this ability to perform new tasks only occurred for models that had a certain number of parameters and were trained on a large-enough dataset.
The idea that quantitative changes in a system (e.g., scaling up language models) can result in new behavior is known as emergence, a concept popularized by the 1972 essay “More is Different” by Nobel laureate Philip Anderson. Emergence has been observed in complex systems across many disciplines such as physics, biology, economics, and computer science.
In a recent paper published in the Transactions on Machine Learning Research, we define emergent abilities in large language models as the following:
An ability is emergent if it is not present in smaller models but is present in larger models.
To characterize the presence of emergent abilities, our paper aggregated results for various models and approaches that came out in just the past two years since GPT-3’s release. The paper looked at research that analyzed the influence of scale — models of different sizes trained with different computational resources. For many tasks, model behavior either predictably grows with scale or unpredictably surge from random performance to above random at a specific scale threshold.
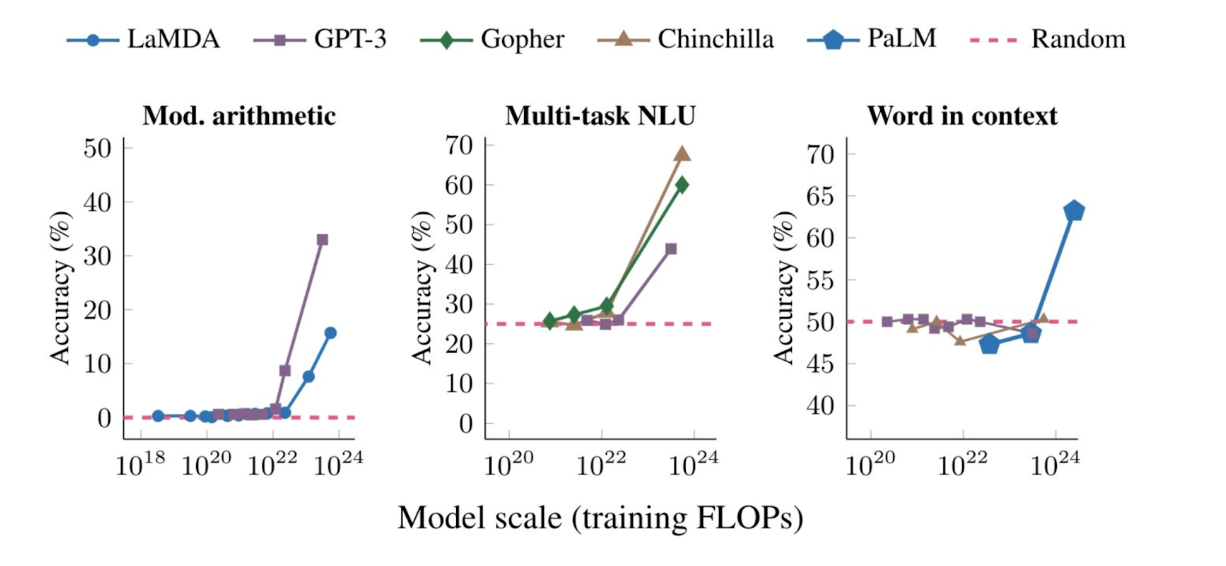
The figure below shows three examples of emergent abilities. The ability to perform arithmetic, take college-level exams (Multi-task NLU), and identify the intended meaning of a word all become non-random only for models with sufficient scale (in this case, we measure scale in training FLOPs). Critically, the sudden increase in performance is not predictable simply by extrapolating from the performance of smaller models.
Another class of emergent abilities includes prompting strategies that augment the capabilities of language models. These strategies are emergent because smaller models cannot use these strategies successfully — only sufficiently large language models can.
One example of a prompting strategy that emerges at scale is “chain-of-thought prompting,” in which the model is prompted to generate a series of intermediary steps before giving the final answer, resembling a “chain of thought.” Chain-of-thought prompting is summarized in figure (A) below — it significantly improves the reasoning abilities of large language models, allowing them to solve multi-step problems that require abstract reasoning, such as math word problems. As shown in (B), on a benchmark of grade-school math problems, chain-of-thought prompting performs worse than directly returning the final answer until a critical size (10^22 FLOPs), at which point it does substantially better.

Emergent abilities are of scientific interest and motivate future research on large language models. Will more scaling of language models lead to further emergent abilities? Why does scaling unlock emergent abilities? Are there ways to unlock such abilities other than scaling? In addition to emergent abilities, are there also new risks that might emerge, such as behaviors that might only exist in future language models? Will new real-world applications of language models become unlocked when certain abilities emerge? These are among the many open questions, and we encourage the community to more deeply examine the mysteries of emergence.
Jason Wei is a Research Scientist at Google Brain. Rishi Bommasani is a second-year Ph.D student in the Stanford Department of Computer Science who helped launch the Stanford Center for Research on Foundation Models (CRFM). Read their study, “Emergent Abilities of Large Language Models,” co-authored with scholars from Google Research, Stanford University, UNC Chapel Hill, and DeepMind.
We thank Percy Liang and Ed H. Chi for their feedback and support on this blog post.
Stanford HAI's mission is to advance AI research, education, policy, and practice to improve the human condition. Learn more.
Related News

Two models working together perform worse than one alone, exposing a critical gap in artificial intelligence capabilities.

Two models working together perform worse than one alone, exposing a critical gap in artificial intelligence capabilities.
AI Hiring Tools Can Yield Racial Bias and Systemic Rejection

The first large-scale study of hiring algorithms in the wild finds concerning patterns to how systems reject candidates.

The first large-scale study of hiring algorithms in the wild finds concerning patterns to how systems reject candidates.

Leveraging statistical concepts from measurement science and education, AI researchers have greatly reduced the computational demand of predicting how the largest of large language models will scale up in the future. It could save millions of dollars in training costs.

Leveraging statistical concepts from measurement science and education, AI researchers have greatly reduced the computational demand of predicting how the largest of large language models will scale up in the future. It could save millions of dollars in training costs.