Generative AI

With increased use of chatbots in mental health contexts, AI developers now rely on human experts to evaluate AI’s responses for “safety” – but experts rarely agree on what’s safe.

With increased use of chatbots in mental health contexts, AI developers now rely on human experts to evaluate AI’s responses for “safety” – but experts rarely agree on what’s safe.

We invited 11 sci-fi filmmakers and AI researchers to Stanford for Stories for the Future, a day-and-a-half experiment in fostering new narratives about AI. Researchers shared perspectives on AI and filmmakers reflected on the challenges of writing AI narratives. Together researcher-writer pairs transformed a research paper into a written scene. The challenge? Each scene had to include an AI manifestation, but could not be about the personhood of AI or AI as a threat. Read the results of this project.

We invited 11 sci-fi filmmakers and AI researchers to Stanford for Stories for the Future, a day-and-a-half experiment in fostering new narratives about AI. Researchers shared perspectives on AI and filmmakers reflected on the challenges of writing AI narratives. Together researcher-writer pairs transformed a research paper into a written scene. The challenge? Each scene had to include an AI manifestation, but could not be about the personhood of AI or AI as a threat. Read the results of this project.

This brief introduces a framework of eight techniques for approximating political neutrality in AI models.

This brief introduces a framework of eight techniques for approximating political neutrality in AI models.



Stanford students across disciplines are teaming up to tackle society’s pressing questions in the age of AI.

Stanford students across disciplines are teaming up to tackle society’s pressing questions in the age of AI.
Current societal trends reflect an increased mistrust in science and a lowered civic engagement that threaten to impair research that is foundational for ensuring public health and advancing health equity. One effective countermeasure to these trends lies in community-facing citizen science applications to increase public participation in scientific research, making this field an important target for artificial intelligence (AI) exploration. We highlight potentially promising citizen science AI applications that extend beyond individual use to the community level, including conversational large language models, text-to-image generative AI tools, descriptive analytics for analyzing integrated macro- and micro-level data, and predictive analytics. The novel adaptations of AI technologies for community-engaged participatory research also bring an array of potential risks. We highlight possible negative externalities and mitigations for some of the potential ethical and societal challenges in this field.
Current societal trends reflect an increased mistrust in science and a lowered civic engagement that threaten to impair research that is foundational for ensuring public health and advancing health equity. One effective countermeasure to these trends lies in community-facing citizen science applications to increase public participation in scientific research, making this field an important target for artificial intelligence (AI) exploration. We highlight potentially promising citizen science AI applications that extend beyond individual use to the community level, including conversational large language models, text-to-image generative AI tools, descriptive analytics for analyzing integrated macro- and micro-level data, and predictive analytics. The novel adaptations of AI technologies for community-engaged participatory research also bring an array of potential risks. We highlight possible negative externalities and mitigations for some of the potential ethical and societal challenges in this field.
All Work Published on Generative AI

PsychAdapter lets researchers dial in on personality traits, age, and mental health characteristics to generate text that sounds like real individuals, opening the door to training simulations and personalized content.
PsychAdapter lets researchers dial in on personality traits, age, and mental health characteristics to generate text that sounds like real individuals, opening the door to training simulations and personalized content.

Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce pyvene, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. pyvene supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how pyvene provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at ‘https://github.com/stanfordnlp/pyvene‘.
Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce pyvene, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. pyvene supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how pyvene provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at ‘https://github.com/stanfordnlp/pyvene‘.

This brief evaluates the impact of authorship labels on the persuasiveness of AI-written policy messages.
This brief evaluates the impact of authorship labels on the persuasiveness of AI-written policy messages.

Percy Liang
.png&w=256&q=80)
.png&w=256&q=100)
Reading Today’s Headlines Through AI: A Real-Time Audit of Six Commercial Chatbots

In a new study, scholars measured how accurately popular AI chatbots answered questions about the emerging news and found substantial regional disparity, dependence on distinct information ecosystems, and acute fragility under imperfect prompts.
In a new study, scholars measured how accurately popular AI chatbots answered questions about the emerging news and found substantial regional disparity, dependence on distinct information ecosystems, and acute fragility under imperfect prompts.

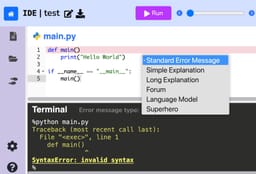
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.