All Work Published on Natural Language Processing

NNetNav learns how to navigate websites by mimicking childhood learning through exploration.
NNetNav learns how to navigate websites by mimicking childhood learning through exploration.

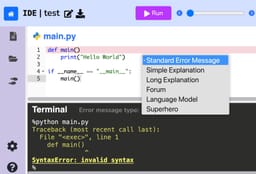
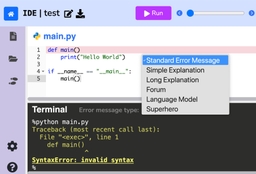
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.
A study led by Stanford HAI Faculty Fellow Johannes Eichstaedt reveals that large language models adapt their behavior to appear more likable when they are being studied, mirroring human tendencies to present favorably.
A study led by Stanford HAI Faculty Fellow Johannes Eichstaedt reveals that large language models adapt their behavior to appear more likable when they are being studied, mirroring human tendencies to present favorably.
Silent Speech Interfaces (SSIs) offer a nonin- vasive alternative to brain-computer interfaces for soundless verbal communication. We in- troduce Multimodal Orofacial Neural Audio (MONA), a system that leverages cross-modal alignment through novel loss functions—cross- contrast (crossCon) and supervised temporal con- trast (supTcon)—to train a multimodal model with a shared latent representation. This archi- tecture enables the use of audio-only datasets like LibriSpeech to improve silent speech recog- nition. Additionally, our introduction of Large Language Model (LLM) Integrated Scoring Ad- justment (LISA) significantly improves recogni- tion accuracy. Together, MONA LISA reduces the state-of-the-art word error rate (WER) from 28.8% to 12.2% in the Gaddy (2020) benchmark dataset for silent speech on an open vocabulary. For vocal EMG recordings, our method improves the state-of-the-art from 23.3% to 3.7% WER. In the Brain-to-Text 2024 competition, LISA per- forms best, improving the top WER from 9.8% to 8.9%. To the best of our knowledge, this work represents the first instance where noninvasive silent speech recognition on an open vocabulary has cleared the threshold of 15% WER, demon- strating that SSIs can be a viable alternative to au- tomatic speech recognition (ASR). Our work not only narrows the performance gap between silent and vocalized speech but also opens new possi- bilities in human-computer interaction, demon- strating the potential of cross-modal approaches in noisy and data-limited regimes.
Silent Speech Interfaces (SSIs) offer a nonin- vasive alternative to brain-computer interfaces for soundless verbal communication. We in- troduce Multimodal Orofacial Neural Audio (MONA), a system that leverages cross-modal alignment through novel loss functions—cross- contrast (crossCon) and supervised temporal con- trast (supTcon)—to train a multimodal model with a shared latent representation. This archi- tecture enables the use of audio-only datasets like LibriSpeech to improve silent speech recog- nition. Additionally, our introduction of Large Language Model (LLM) Integrated Scoring Ad- justment (LISA) significantly improves recogni- tion accuracy. Together, MONA LISA reduces the state-of-the-art word error rate (WER) from 28.8% to 12.2% in the Gaddy (2020) benchmark dataset for silent speech on an open vocabulary. For vocal EMG recordings, our method improves the state-of-the-art from 23.3% to 3.7% WER. In the Brain-to-Text 2024 competition, LISA per- forms best, improving the top WER from 9.8% to 8.9%. To the best of our knowledge, this work represents the first instance where noninvasive silent speech recognition on an open vocabulary has cleared the threshold of 15% WER, demon- strating that SSIs can be a viable alternative to au- tomatic speech recognition (ASR). Our work not only narrows the performance gap between silent and vocalized speech but also opens new possi- bilities in human-computer interaction, demon- strating the potential of cross-modal approaches in noisy and data-limited regimes.
AI’s Fairness Problem: When Treating Everyone the Same is the Wrong Approach

Current generative AI models struggle to recognize when demographic distinctions matter—leading to inaccurate, misleading, and sometimes harmful outcomes.
Current generative AI models struggle to recognize when demographic distinctions matter—leading to inaccurate, misleading, and sometimes harmful outcomes.

How Persuasive Is AI-generated Propaganda?

Can large language models, a form of artificial intelligence (AI), generate persuasive propaganda? We conducted a preregistered survey experiment of US respondents to investigate the persuasiveness of news articles written by foreign propagandists compared to content generated by GPT-3 davinci (a large language model). We found that GPT-3 can create highly persuasive text as measured by participants’ agreement with propaganda theses. We further investigated whether a person fluent in English could improve propaganda persuasiveness. Editing the prompt fed to GPT-3 and/or curating GPT-3’s output made GPT-3 even more persuasive, and, under certain conditions, as persuasive as the original propaganda. Our findings suggest that propagandists could use AI to create convincing content with limited effort.
Can large language models, a form of artificial intelligence (AI), generate persuasive propaganda? We conducted a preregistered survey experiment of US respondents to investigate the persuasiveness of news articles written by foreign propagandists compared to content generated by GPT-3 davinci (a large language model). We found that GPT-3 can create highly persuasive text as measured by participants’ agreement with propaganda theses. We further investigated whether a person fluent in English could improve propaganda persuasiveness. Editing the prompt fed to GPT-3 and/or curating GPT-3’s output made GPT-3 even more persuasive, and, under certain conditions, as persuasive as the original propaganda. Our findings suggest that propagandists could use AI to create convincing content with limited effort.
