All Work Published on Foundation Models
Transparency in AI is on the Decline
A new study shows the AI industry is withholding key information.
A new study shows the AI industry is withholding key information.
Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce pyvene, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. pyvene supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how pyvene provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at ‘https://github.com/stanfordnlp/pyvene‘.
Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce pyvene, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. pyvene supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how pyvene provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at ‘https://github.com/stanfordnlp/pyvene‘.

This brief presents an analysis of Chinese AI startup DeepSeek’s talent base and calls for U.S. policymakers to reinvest in competing to attract and retain global AI talent.
This brief presents an analysis of Chinese AI startup DeepSeek’s talent base and calls for U.S. policymakers to reinvest in competing to attract and retain global AI talent.


Five teams will use the funding to advance their work in biology, generative AI and creativity, policing, and more.
Five teams will use the funding to advance their work in biology, generative AI and creativity, policing, and more.

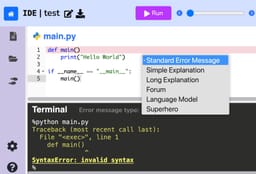
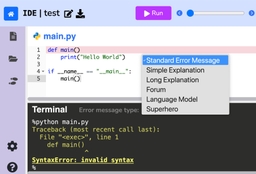
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.
In this paper, we evaluate the most effective error message types through a large-scale randomized controlled trial conducted in an open-access, online introductory computer science course with 8,762 students from 146 countries. We assess existing error message enhancement strategies, as well as two novel approaches of our own: (1) generating error messages using OpenAI's GPT in real time and (2) constructing error messages that incorporate the course discussion forum. By examining students' direct responses to error messages, and their behavior throughout the course, we quantitatively evaluate the immediate and longer term efficacy of different error message types. We find that students using GPT generated error messages repeat an error 23.1% less often in the subsequent attempt, and resolve an error in 34.8% fewer additional attempts, compared to students using standard error messages. We also perform an analysis across various demographics to understand any disparities in the impact of different error message types. Our results find no significant difference in the effectiveness of GPT generated error messages for students from varying socioeconomic and demographic backgrounds. Our findings underscore GPT generated error messages as the most helpful error message type, especially as a universally effective intervention across demographics.
What Makes a Good AI Benchmark?

This brief presents a novel assessment framework for evaluating the quality of AI benchmarks and scores 24 benchmarks against the framework.
This brief presents a novel assessment framework for evaluating the quality of AI benchmarks and scores 24 benchmarks against the framework.
